激光雷达点云上采样调研
激光雷达点云上采样相关论文调研。
研究背景
概述
点云超分辨率关注点云的密度以及几何信息。对于给定的点云 \(P\) ,我们希望得到更加密集的点云 \(Q\) ,能够描述 \(P\) 所在的底层形状。
对于激光雷达点云,这个问题要特殊一些。常规的点云上采样容易受到点云数据不规则特性的困扰,但激光雷达点云具有规则的分布,这受益于激光雷达的环状扫描方式。
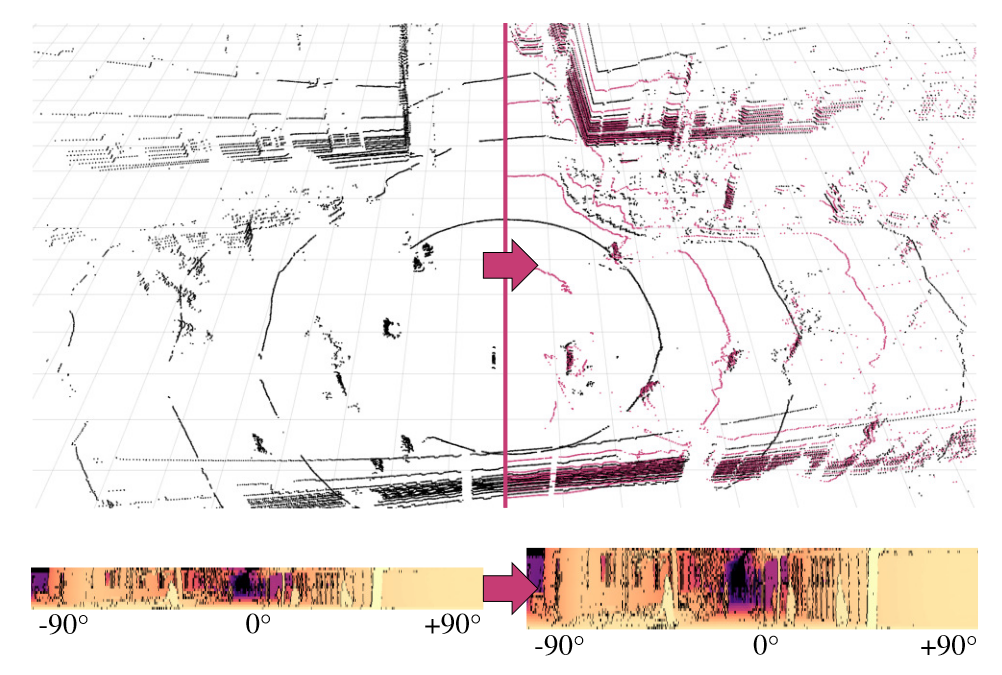
鉴于激光雷达的扫描方式,一个自然的想法是将点云投影为球面坐标,即: \[ \begin{cases} \begin{aligned} \varphi &= \arctan\left(z\big/\sqrt{x^2+y^2} \right) \\ \theta &= \arctan(y/x)\\ d &=\sqrt{x^2+y^2+z^2} \end{aligned} \end{cases} \] 此时在 \(\varphi-\theta\) 平面上,点的分布是规则的,这有利于后续的栅格化和上采样。使用这种投影的上采样方法通常总结为基于格网的方法。
需要注意的是,有的激光雷达点云在垂直方向上并不均匀分布,例如 Pandar64 将 \(3/4\) 的线束集中在了 \((-6°,+2°)\) ,而垂直视场角为 \((-25°,+15°)\) ,但这样的激光雷达目前还不多见。
问题描述
对于点云 \(P\) ,可将其记作一系列扫描线的集合,即 \(P=\{L_i \, |i=1,2,\dots,N_P\}\) ,其中 \[ L_i=\left\{(x,y,z)\in P \, \middle|\arctan\left(z\big/\sqrt{x^2+y^2}\right)=\varphi_i \right\}, \] 表示第 \(i\) 条扫描线,我们希望预测点云 \(Q=\{L_i \, |i=1,2,\dots,N_Q\}\) ,满足 \(N_Q>N_P\) ,且保有 \(P\) 的几何特征和扫描线结构。同时我们希望点云 \(Q\) 在同样的下游算法上表现出优于 \(P\) 的性能。
研究现状
CNN-based synthesis of realistic high-resolution LiDAR data
上采样
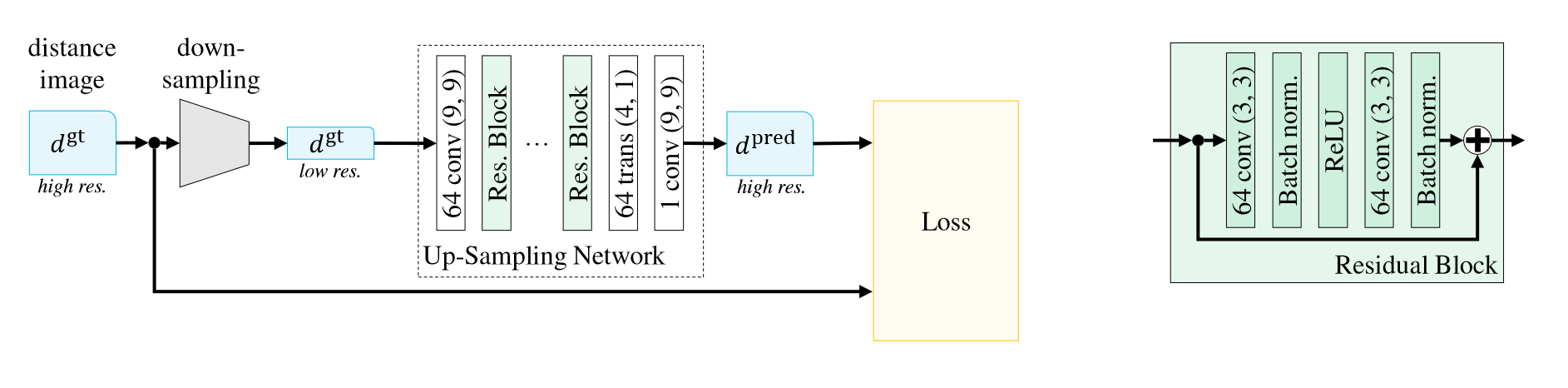
下图展示了网络的总体框架。对于低分辨率图像,其特征提取步骤通过一系列残差块执行,上采样则通过转置卷积(文中称分数跨步卷积)实现。在第一层和最后一层使用了 \(9\times 9\) 的卷积,中间残差块中都是 \(3\times 3\) 。
修正的逐点损失函数
论文考虑到图像中大量存在的缺失点,将 \(\mathcal{L}_1、\mathcal{L}_2\) 损失修正为只对比非缺失点,记作集合 \(V\subset I\) ,即: \[ \mathcal{L}_d^\alpha = \sum_{(i,j)\in V}\left| d_{ij}-\hat{d}_{ij} \right|^{\alpha},\alpha=1,2 \]
感知损失
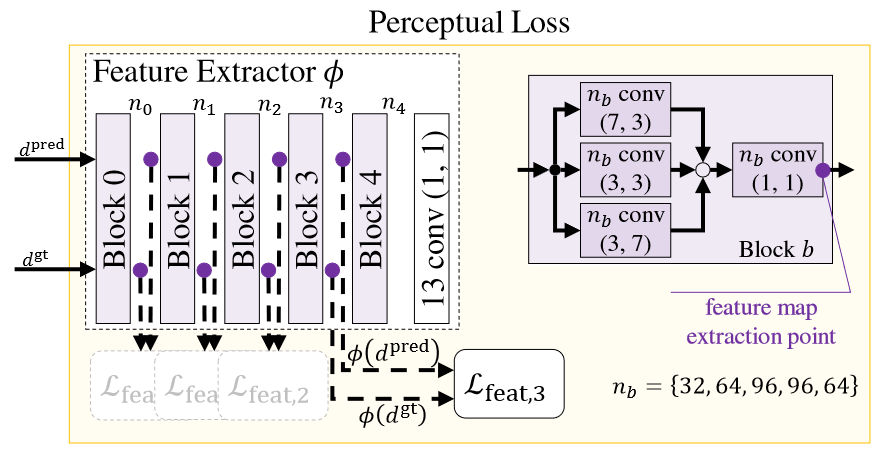
逐点损失鼓励图像输出较为平滑的结果,因为它表示了平均误差。同时逐点损失只能在像素层面比较,无法获取高频信息。因此有许多方法使用感知模块来表征损失,使生成的图像更真实。论文采用了一个预训练好的特征提取器 \(\phi\) ,将预测图和实际图作为输入,并计算每一层的损失: \[ \mathcal{L}_{f}=\sum_{c}\sum_{(i,j)\in I}\left| \phi_c(d)_{ij}-\phi_c(\hat{d})_{ij} \right| \] 其中 \(\phi_c\) 对应了前 \(c\) 层特征提取器。
语义一致性损失
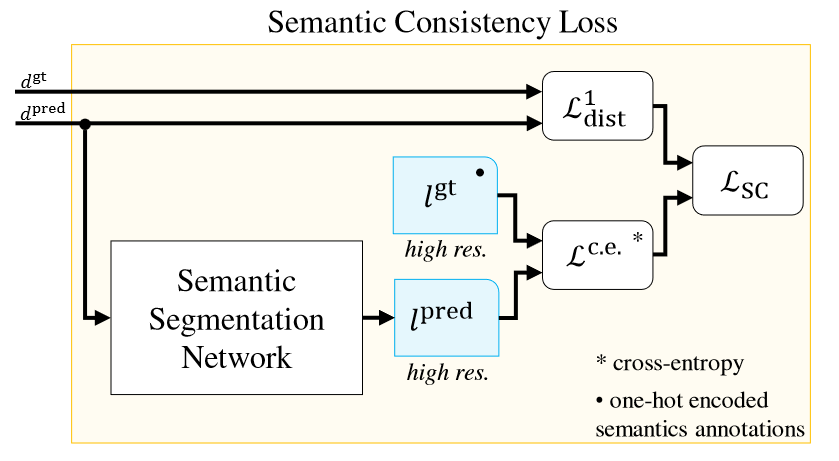
语义一致性损失则利用了语义分割网络,以交叉熵方式比较两次扫描。对每个点预测一个语义类别概率,并和真值(one-hot 编码)进行比较,得到交叉熵损失 \(\mathcal{L}_{ce}\) 。但仅有交叉熵损失无法约束点云的几何结构,因此通过可训练的权重参数将两个损失整合在一起: \[ \mathcal{L}_{sc}=\frac{1}{2\sigma_r^2}\mathcal{L}_{d}^{1}+\frac{1}{\sigma_c^2}\mathcal{L}_{ce}+\log\sigma_r+\log\sigma_c \] 这一结果来自 Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics ,它通过对数似然推导了语义损失和回归损失的整合,但论文这里似乎把正则项抄错了(丢了两个平方)。
评估指标
MAE, MSE, mIoU 以及问卷投票。
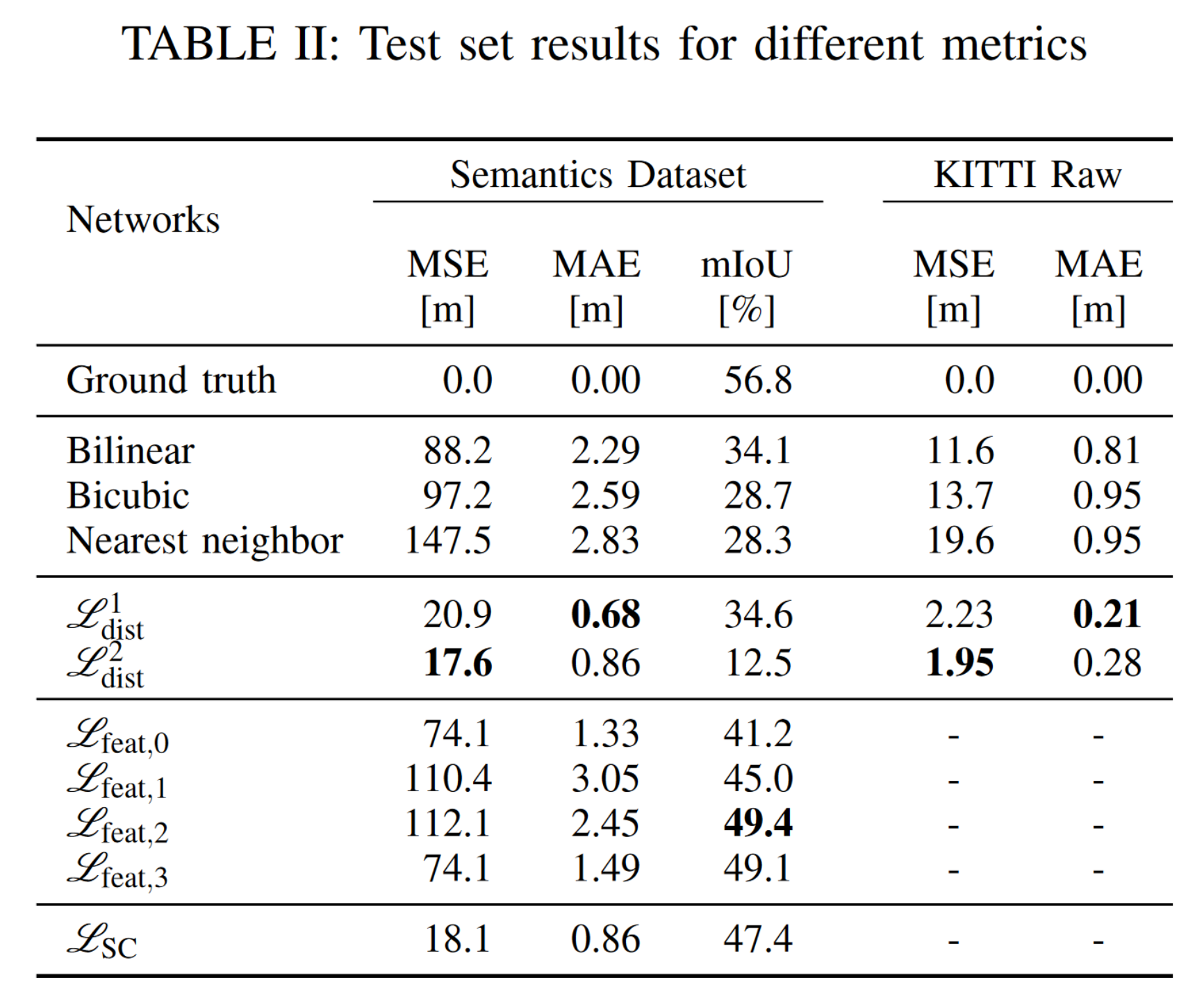
结论
论文只实现了两倍上采样,从实验结果来看,使用逐点损失的 MAE 和 MSE 最高,使用感知损失的 mIoU 最高,使用语义的效果不好。但这些结论几乎没什么帮助。
Simulation-based Lidar Super-resolution for Ground Vehicles
方法
第一篇开源的工作,也是该任务下被引最多的。其思路很简单:带有转置卷积的 U-Net 用于重建深度,蒙特卡洛 Dropout 用于克服噪声值。
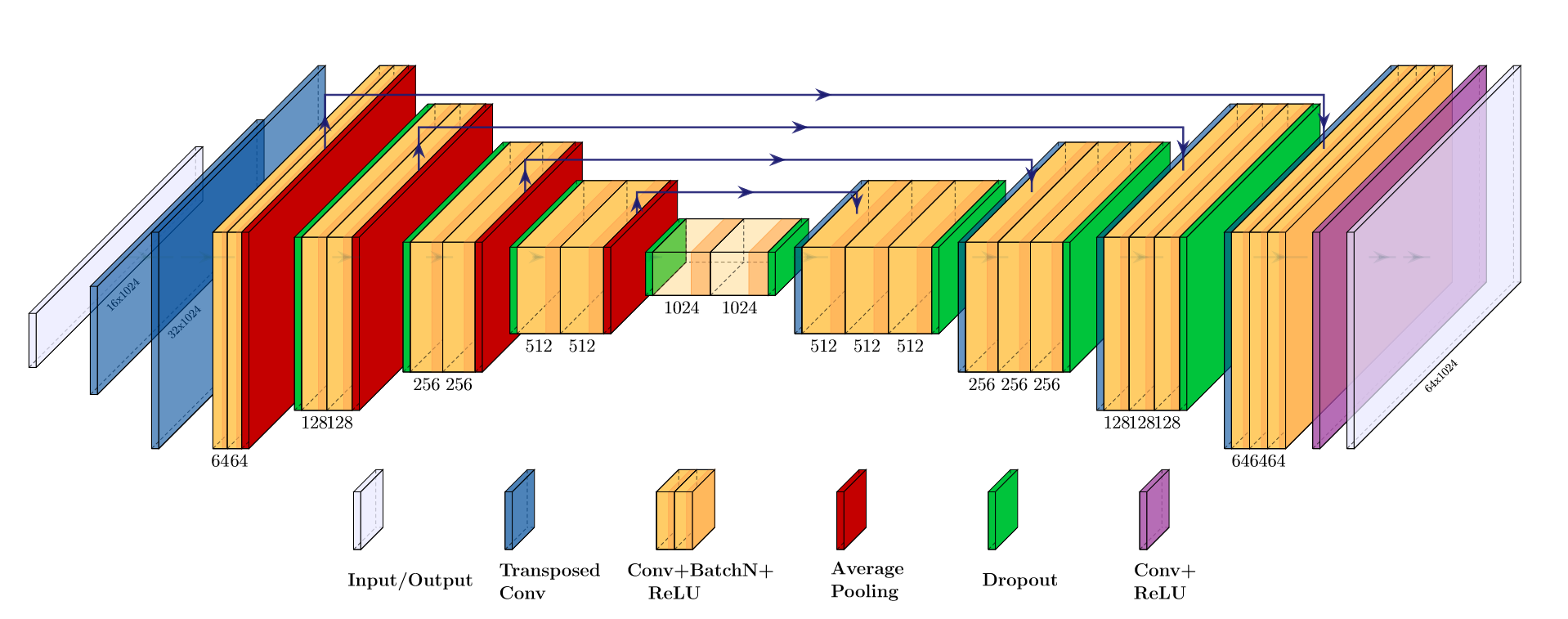
MC-Dropout 的想法是:在测试阶段也应用 Dropout 进行多次预测,从而获取多个不同的值。相当于将多个子网络的预测进行集成。对于多次预测变化较大的点,输出较低的置信度,并取平均值作为最终预测值。Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning 论证了 MC-Dropout 可以被看作高斯过程中的近似贝叶斯推理,表达为下式: \[ p(y^*|\mathbf{x}^*,\mathcal{D})\propto \int p(y^*|\theta^*)p(\mathbf{x}^*,\mathcal{D}|\theta^*)\mathrm{d}\theta^* \\ \Downarrow \\ p(y^*|\mathbf{x}^*)=\frac{1}{T}\sum_{t=1}^{T}p(y^*|\mathbf{x}^*,\theta^*_t) \] MC-Dropout 在直觉上接近机器学习中的 Bagging,但它只需要一个模型。论文实验了有无 MC-Dropout 的两种效果,认为它对减少噪声有很大帮助。
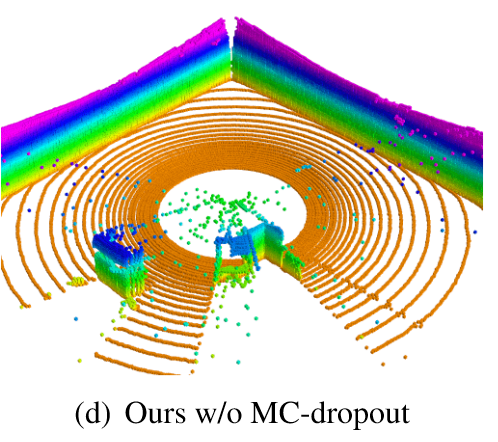
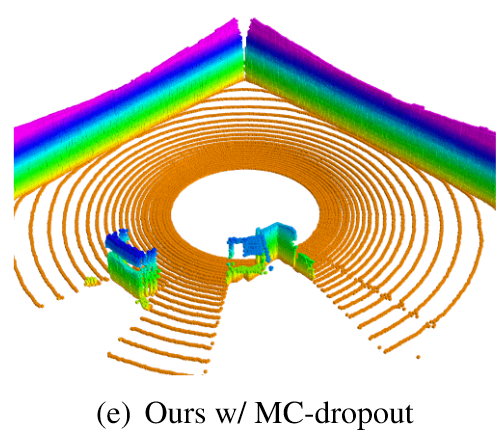
评价指标
通过生成预测点和 ground truth 的占用地图,绘制 ROC 曲线以及 AUC 的值。
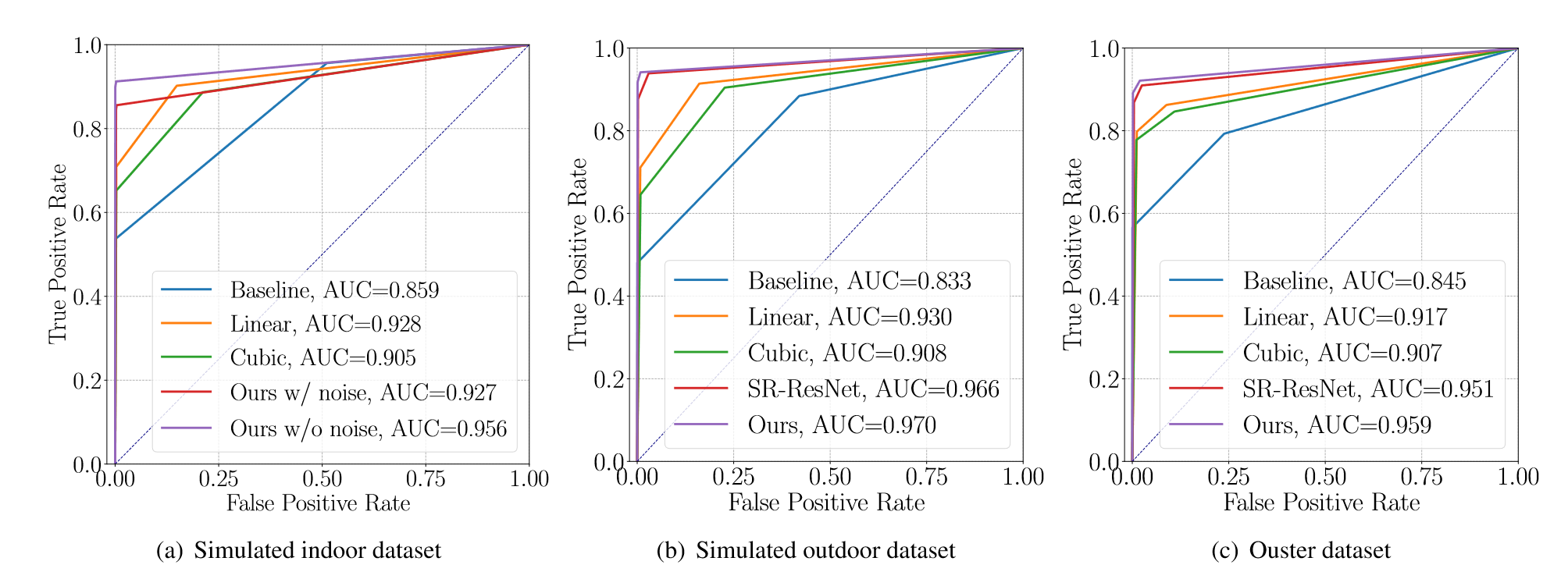
T-UNet: A Novel TC-Based Point Cloud Super-Resolution Model for Mechanical LiDAR
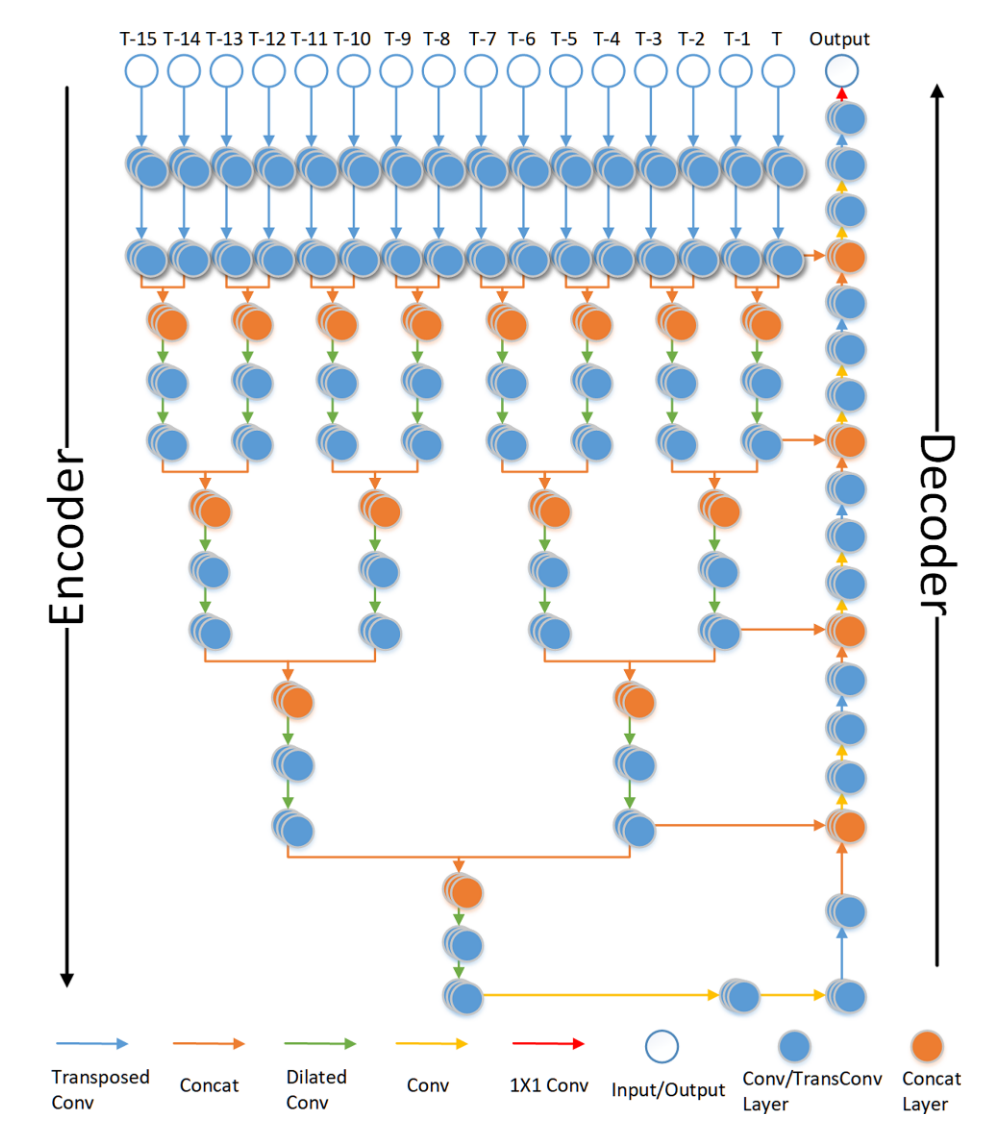
代码:donkeyofking/lidar-sr 。其主要思路是利用点云帧序列,而非单帧点云。
方法
- 首先将 \(16\) 帧序列点云分别通过转置卷积进行上采样。将相邻两个特征图拼接,并通过(膨胀)卷积提取特征。论文用膨胀卷积取代了池化层,以减少信息的丢失。
- 重复上述步骤,直至得到一个特征图。然后通过一系列的转置卷积上采样,并和之前的特征图连接,这里和 U-Net 的结构相同。
- 采用 SSIM 作为损失函数。
评价指标
峰值信噪比 (PNSR), MSE, 结构相似性指数 (SSIM)。
Channel Attention based Network for LiDAR Super-resolution
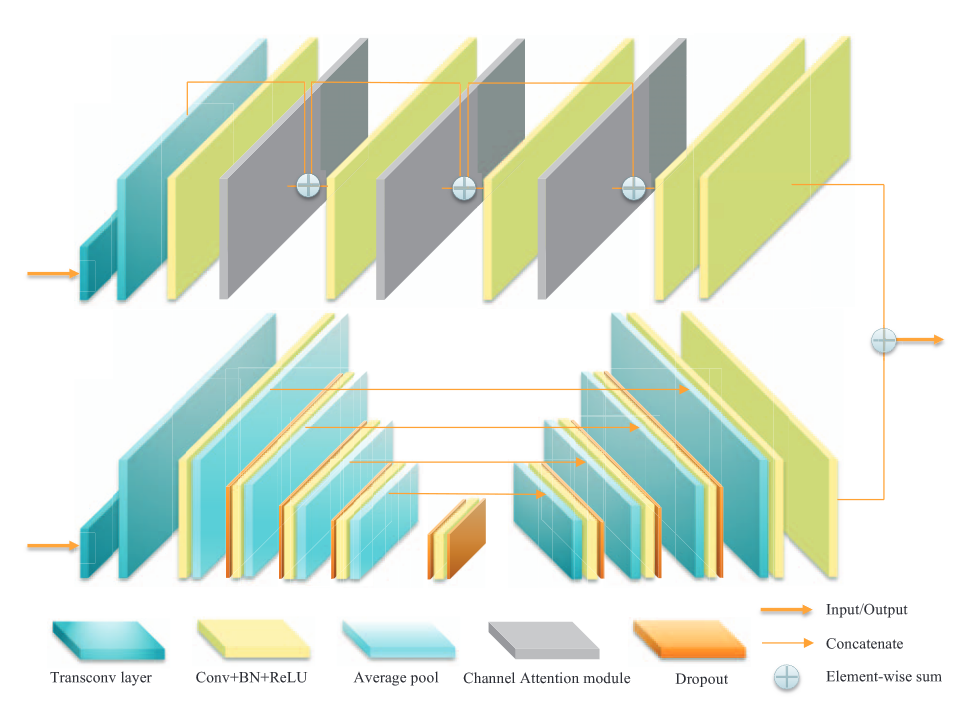
无代码。网络架构由一个 U-Net 和一个基于通道注意力的重建块组成。
基于通道注意力的重建块
从图中看到,首先是两个转置卷积上采样四倍,然后就是不断复用卷积层和通道注意力模块,并使用残差连接。最后用两个卷积层回归深度值,并和 U-Net 提取的信息逐点相加。论文希望 U-Net 能够捕获边缘信息,使重建更准确(但是并没有对提取边缘这一点做监督或者约束,比较奇怪,可能是玄学吧)。
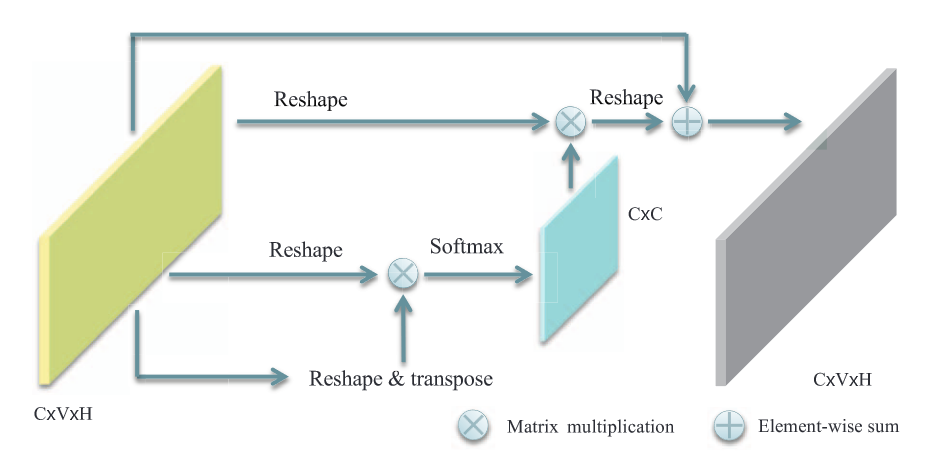
通道注意力的结构就是最基本的自注意力机制,它关注不同通道之间的相关性(原文却说“每个通道上相邻像素之间的相关性”,可能是笔误)。首先将图像特征 \(C\times V \times H\) 展平成 \(C\times VH\) 的特征,和 \(VH \times C\) 的矩阵执行点积,通过 SoftMax 得到 \(C\times C\) 的注意力矩阵,然后和原来的特征矩阵相乘,得到新的特征图。
环形填充
球面投影需要一个角度来分割投影图,然后展平,因此在分割处提取不到真实的局部特征。论文的方法很简单,就是把图像往两边 padding,补充回丢掉的局部信息。
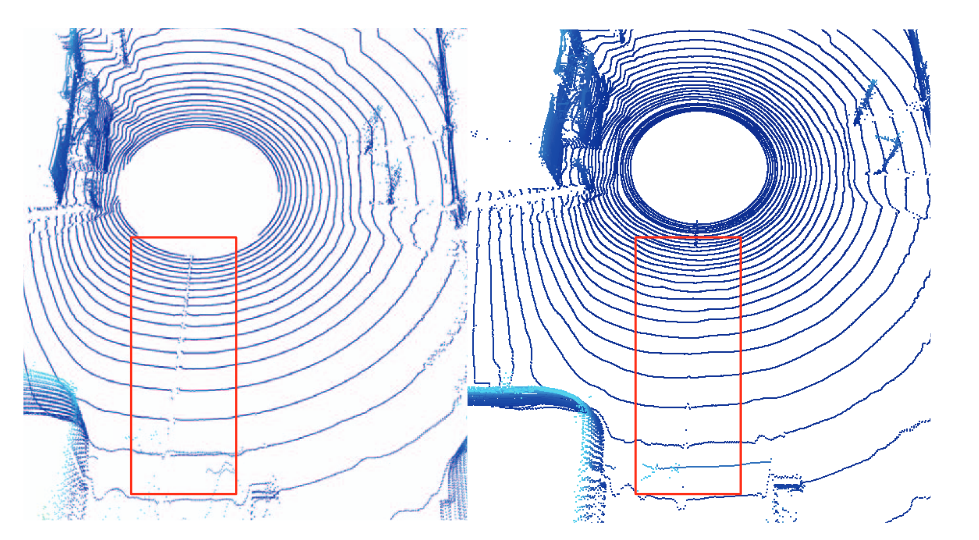
评估指标
只采用了一个 MAE 。
LiDAR Super-Resolution Based on Segmentation and Geometric Analysis
无代码。这是一个步骤较多的无监督方法,并且基于点而非格网,但采用的是球面投影,因此同样保留扫描线结构。
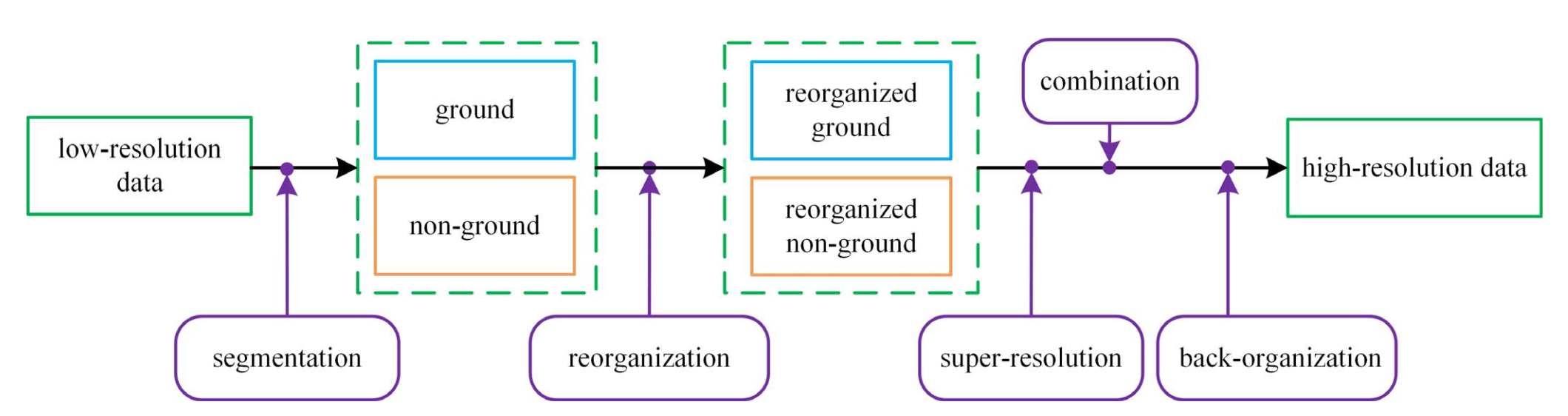
地面点分割
这一步骤在 \(xyz\) 坐标上进行,更准确的说,在每一列扫描线上进行。
对于输入点 \(P_l\) ,目标是分割得到地面点 \(P_g\) 和非地面点 \(P_{ng}\) 。考虑一列扫描点,点分布如下图所示。
- 首先找到 \(z\) 值最小的点,向两边顺序搜索,得到相邻点的向量 \(V_l\) ;同时从最低点出发,连接所有点,得到向量 \(V_r\) ;
- 求向量点积 \(V_l \cdot V_r\) ,并通过点积的绝对值选取种子点(论文这里讲得不太清楚,应该就是求向量夹角)。最后通过一个 \(z\) 值的低通滤波得到地面种子点;
- 基于种子点,利用最小二乘拟合一条直线,将距离直线一定阈值内的点纳入地面点,其余点纳入非地面点。对一圈的点执行上述操作,实现分割。
坐标重组
坐标重组就是球面投影。但论文这里没有采用栅格化为图像的方式,而是保留三维坐标 \((h,v,d)\) ,避免了任何信息损失。其中 \(h,v\) 分别表示水平角和垂直角,\(d\) 表示距离。
超分辨率
针对地面点和非地面点,采用两种上采样思路。
地面点上采样
将地面点视作平面,若上下两个像素都是地面点,则考虑三角形角平分线的性质。这里的推导很简单,设前后两个点的球面坐标分别为:
\[
\begin{cases}
p_A = [I_i\cdot H_{\textrm{res}},a,v_1]
\\
p_B = [I_i\cdot H_{\textrm{res}},b,v_5]
\end{cases}
\] 则 \(v_3=(v_1+v_5)/2\)
,只需求 \(OD\) 的长度,结果如下:
\[
d = \frac{2ab}{a+b}\cos\frac{\alpha}{2}
\]
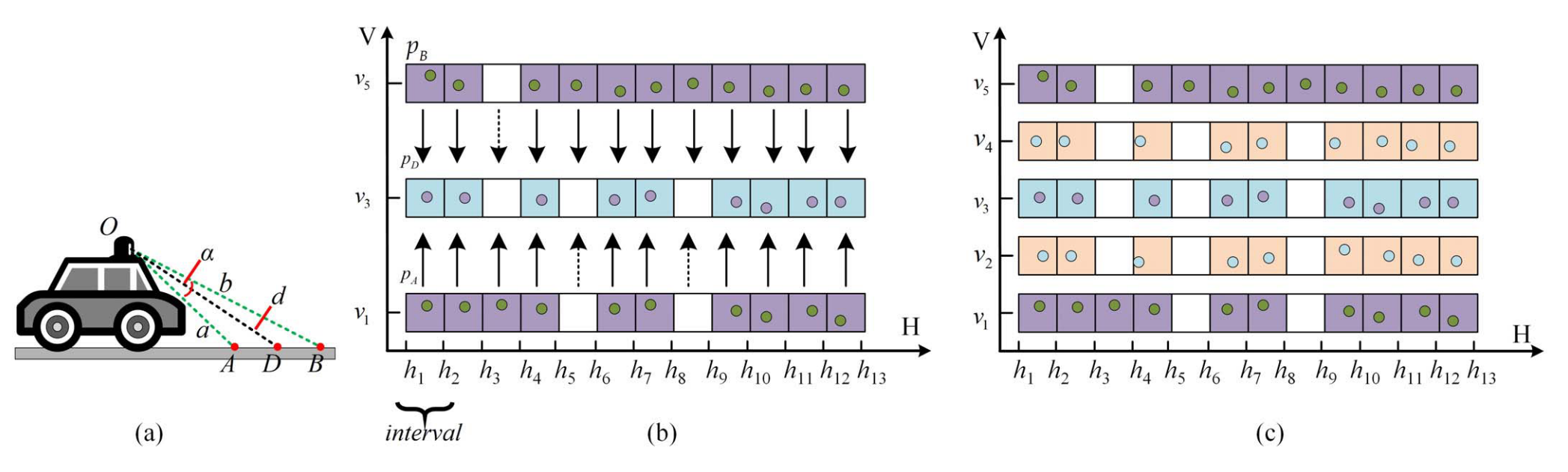
地面点还有一个优化,大致是对空缺点进行了讨论,然后用局部的平滑细化点。
非地面点上采样
从俯视图上,观察到非地面点呈现簇的分布,即同一物体的点之间相距较进。简单聚类后对每个物体进行上采样,将点分为物体内的点和物体间的点。对于物体间的点,由于缺乏先验知识,无法归类,为了提升远处物体的点数量,论文直接将其归到更远的物体上。
评价指标
Hasdorff 距离和 CD 。
Fast Point Clouds Upsampling with Uncertainty Quantification for Autonomous Vehicles
无代码。基本思路是用神经过程(NP)取代了 MC-Dropout,去实现更快速的不确定性量化。MC-Dropout 需要多次前向推理,会比较占用资源。从它的输出结果来看,不确定性较大的点依然是集中在边缘区域。
使用 Conv-NPs 的上采样
对于低分辨率图像,论文用空白的掩码 \(M_c\) 替代了转置卷积,直接增加图像的行数。与之对应的有 \(M_t\) ,表示已知的部分。 \[ M_c(i,j)=\begin{cases} \begin{aligned} 1&, \text{if} \ \ (r_{up}|i) \\ 0&, \text{otherwise} \end{aligned} \end{cases} \] 后续的方法分为四个模块。首先通过特征提取器,分别从掩码和扩大后的图像中提取特征图,并连接在一起。 \[ \begin{cases} e=\zeta(M_c)\in \mathbb{R}^{U_{\mathcal{H}}\times V_{\mathcal{H}}\times K} \\ e'=\zeta(\mathcal{I_P})\in \mathbb{R}^{U_{\mathcal{H}}\times V_{\mathcal{H}}\times K} \\ \end{cases} \Rightarrow \epsilon=e \oplus e' \] 通过通过卷积层聚合邻域特征: \[ e_C = \gamma(\epsilon)\in \mathbb{R}^{U_{\mathcal{H}}\times V_{\mathcal{H}}\times 2} \] 再由掩码 \(M_t\) 和特征 \(e_C\) 预测一组高斯分布: \[ v=(\mu, \sigma)=\Phi(M_t,e_C) \] 得到了均值图像和方差图像,从而滤除不确定性较大的点。
损失函数
由于输出了不确定性,实际上估计的是一个高斯分布。因此有条件负对数似然损失: \[ Loss = -\mathbb{E}_{\mathcal{D}}\left[ \frac{1}{U_{\mathcal{H}}\times V_{\mathcal{H}}}\sum_{i,j}\log p_{i,j}(r_{i,j}^{g}|v_{i,j})\right] \] 其中 \(r_{i,j}^{g}\) 表示像素点 \((i,j)\) 上的真实距离。
评价指标
仅适用了 MAE 。
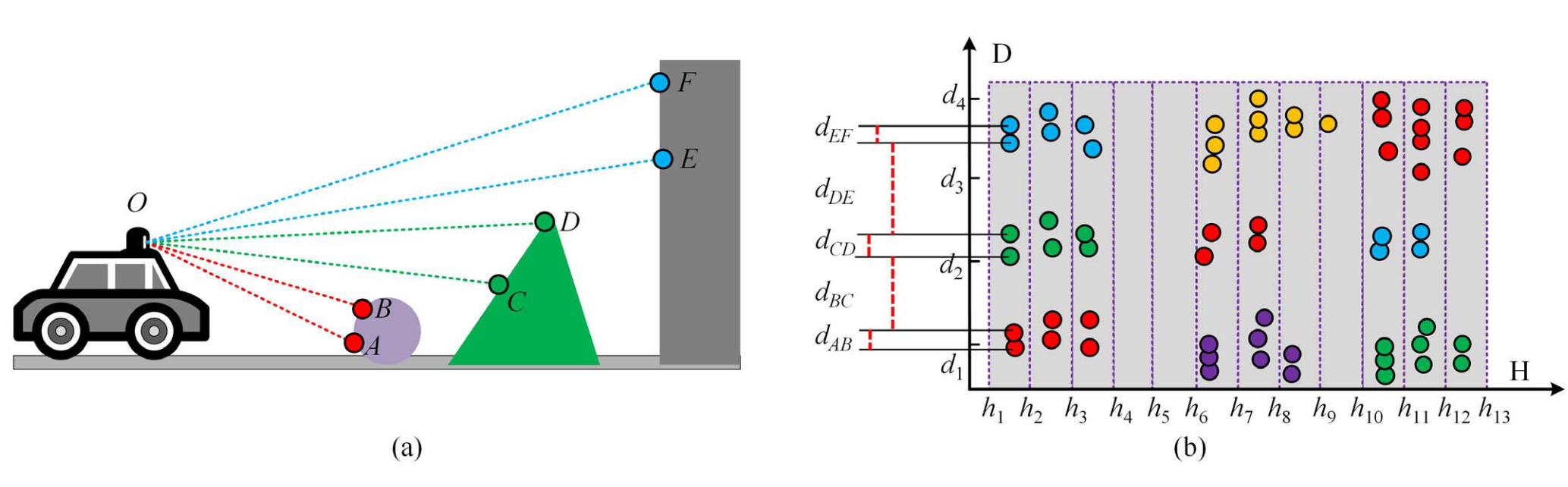
Implicit LiDAR Network: LiDAR Super-Resolution via Interpolation Weight Prediction
代码:PinocchioYS/iln 。整体思路比较简单,对于任意一条查询射线,对其四个邻域点的特征进行注意力,求得权重,然后对距离加权。ILN 是第一个实现任意分辨率的,并且无需不确定性量化。
LIIF
LIIF 是这篇文章的灵感来源,发表在 CVPR2021 。对于二维特征图 \(M \in \mathbb{R}^{H\times W\times D}\) ,定义一个对于所有图像相同的解码器 \(f_\theta\) ,其作用为: \[ s=f_\theta(z,x) \] 其中 \(z\) 是一个向量,\(x\in \mathcal{X}\) 是一个二维坐标,\(s\) 为预测信号(通常为 RGB 值)。因此每一个 \(z\) 对应了一个函数,即: \[ z\mapsto f_\theta(z,\cdot):\mathcal{X}\rightarrow\mathcal{S}, \] 假设特征向量在二维空间均匀分布,为每一个特征分配一个二维坐标。对于连续图像 \(I(i)\) ,坐标 \(x_q\) 处的 RGB 值定义为: \[ I(x_q)=f_\theta(z^*, x_q-v^*), \] 其中 \(z^{*}\) 是距离 \(x_q\) 最近的一个特征向量,\(v\) 是对应的坐标。
简而言之,对于任何一个需要预测的位置,找到离它最近的那个已知点,将该点的特征以及距离送入一个网络,输出预测值。仅此而已。这就好比点云上采样时,从一个点出发生成一系列点。
但这样做还不够,因为一个特征过于单调。论文使用了一个叫“特征展开”的步骤,将 \(M\) 中每个位置的 \(3\times 3\) 邻域串联起来,得到新的特征图: \[ M_{jk}=\text{Concat}(\{M_{j+l,k+m}\}_{l,m \in \{-1,0,1\}}), \] 此外,由于两个像素连线中点处,会发生“跳变”的情况,因为 \(z^*\) 发生了变化。为保证预测的连续性,将预测图像改写为: \[ I(x_q)=\sum_{t\in \{00,01,10,11\}}\frac{S_t}{S}\cdot f_\theta(z^*_t, x_q-v^*_t), \] 也就是将最近的四个像素的预测值取加权平均。权重系数和 \(x_q\) 到 \(v^*_t\) 构成的矩形面积 \(S_t\) 成正比。
除此之外还不够,由于 \(f_\theta\) 预测了一个离散点的值,而我们实际上想要生成一个像素的值。这类似于 NeRF 与 Mip-NeRF 的区别,论文将像素的范围考虑在内,即: \[ s=f_{cell}(z,[x,c]) \] 其中 \(c=[c_h,c_w]\) ,表示查询像素的大小。
ILN
LIIF 通过周边信息直接预测了值,而 ILN 尝试预测权重,以在距离图像上取得比较稳定的效果。在 LIIF 中,权重是可以直接计算的。记权重函数为 \(h\) ,值函数为 \(g\) ,则 LIIF 可以表示为: \[ \hat{r}=\sum_{t}^{4}g(\cdot)h(\cdot |\theta)=\sum_{t}^{4}\frac{S_t}{S}\cdot h(z_t|\theta) \] 为了直接利用周边点的距离值,ILN 直接预测权重: \[ \hat{r}=\sum_{t}^{4}g(\cdot |\theta)h(\cdot )=\sum_{t}^{4} g(z_t|\theta)\cdot r_t \] 其主要思路很简单:首先对输入图像做特征提取,得到特征图;然后对于每个查询射线 \(q\) ,找到最近的四个像素,将每个像素的相对距离 \(\Delta q_t\) 编码后和特征 \(z_t\) 组合在一起,得到 \(z_t'\) 向量;之后通过一组自注意力块和线性层,直接获得四个权重值。
评价指标
MAE、IoU、Precision、Recall 以及 F1。
HALS: A Height-Aware Lidar Super-Resolution Framework for Autonomous Driving
无代码。但这一篇写得很详细,有比较多的分析和对过往方法的总结。
方法
作者认为距离图像的上下部分具有不同的高度分布规律,即上部分距离较远,方差较大,下部分距离较进,方差较小。这意味着上部区域具有更广泛的距离值分布,因此具有更高的空间频率。
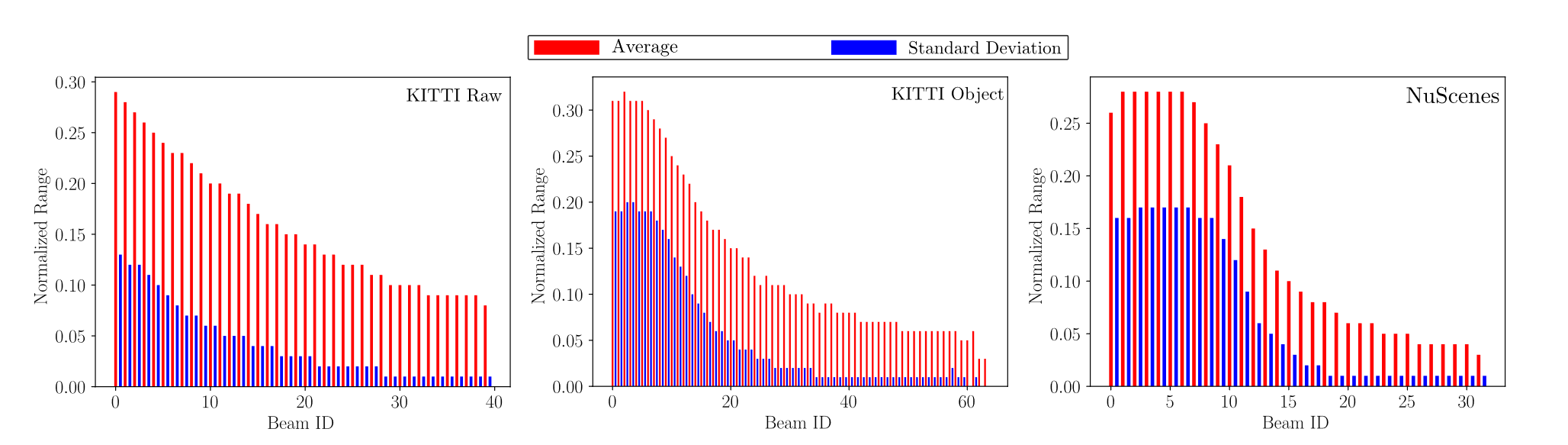
因此论文在距离图的不同高度使用不同的策略。远处物体被压缩,且通常出现在上方,因此关注小区域;近处物体较大,且通常出现在下方,因此关注较大的区域。所以论文问用两个感受野提取的特征进行上采样,并预测两个感受野的掩码,从而进行加权融合。
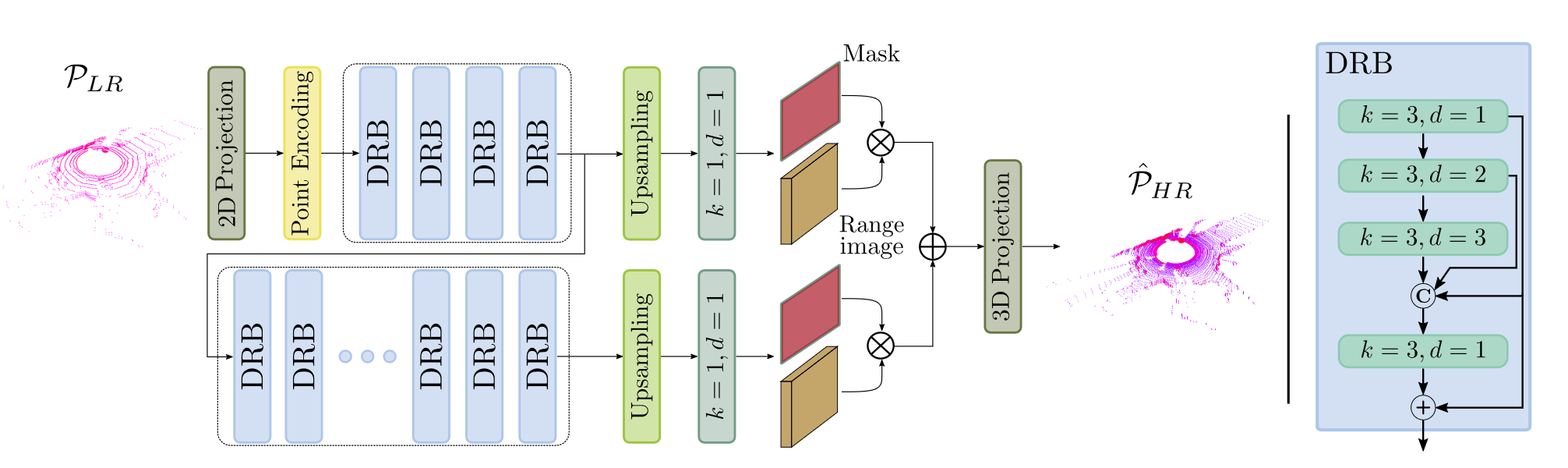
DRB 是膨胀残差块,在 RangeRCNN: Towards Fast and Accurate 3D Object Detection with Range Image Representation 中提出,是专为激光雷达投影后图像设计的。
不同距离的物体的尺度表现出显着的差异。为了更好地适应不同的尺度并获得更灵活的感受野,我们设计了膨胀残差块(DRB),它将膨胀卷积插入到正常残差块中。
应用三个具有不同扩张率 \(\{1,2,3\}\) 的 \(3\times3\) 卷积来提取具有不同感受野的特征。三个扩张卷积的输出被连接起来,然后是一个 1 × 1 卷积,以融合具有不同感受野的特征。残差连接用于添加融合特征和输入特征。
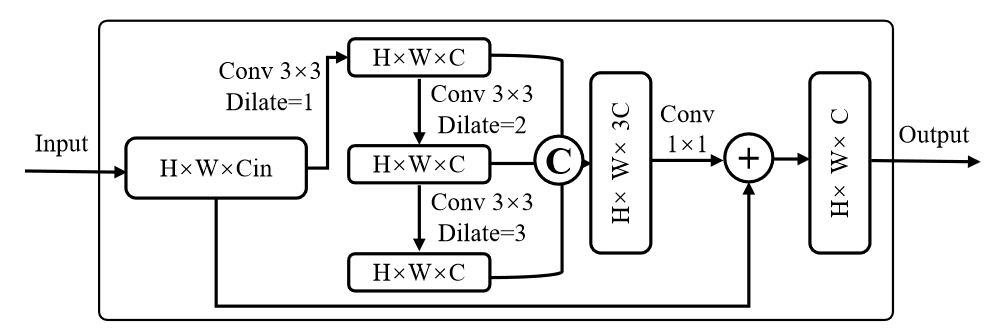
但是作者这里没有说上采样层的结构。最终预测一个 \(C+1\) 维的特征图,最后一维作为掩码。两个掩码进行 SoftMax 得到权重。
评价指标
EMD、CD、MAE、RMSE、IoU、Precision、Recall、F1。
SGSR-Net: Structure Semantics Guided LiDAR Super-Resolution Network for Indoor LiDAR SLAM
CASE 模块
为了缓解物体边界周围的边缘膨胀和混合,采用了 squeeze and excitation 方法和注意力机制结合。
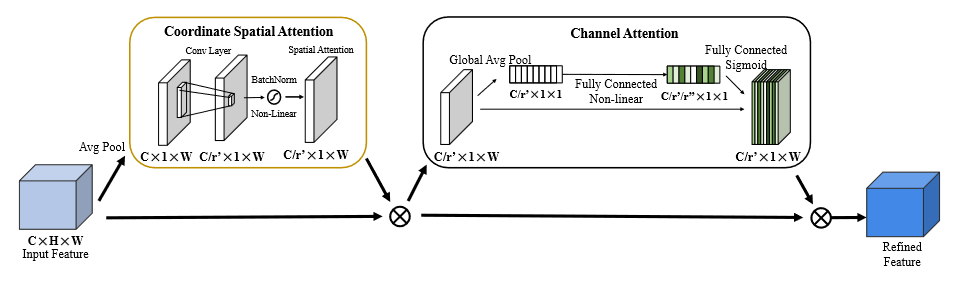
具体来说,对于输入的特征图 \((C\times H \times W)\) 做平均池化,得到压缩的特征 \((C\times 1\times W)\) ,再通过卷积将特征压缩到 \(C/r'\) ,随后对特征图做批量归一化,并输入 sigmoid 得到注意力权重 \((C/r' \times 1\times W)\) ,将其和原始特征矩阵相乘(没看懂咋乘的)。整体结构依然是 U-Net 。将 CASE 模块放在最前面,以避免在 Dropout 中丢失必要的信息。
SGR 模块
这部分主要是针对室内点云的特性,做一些简单的分割以引入语义信息。
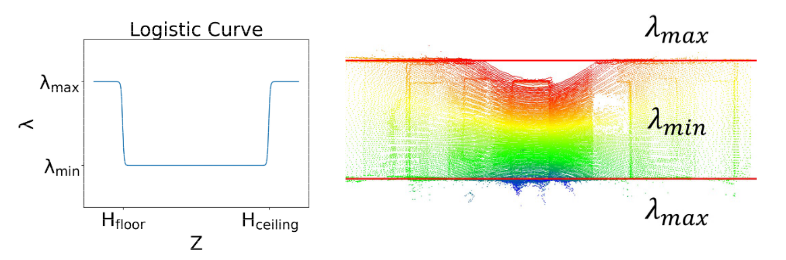
首先统计单帧点云的 \(z\) 值直方图,找出频率最高的两个,作为地面和天花板的高度 \(h_{floor},h_{ceiling}\) 。为了提升相邻帧检测的一致性,取前后 \(N\) 帧的中值滤波结果。
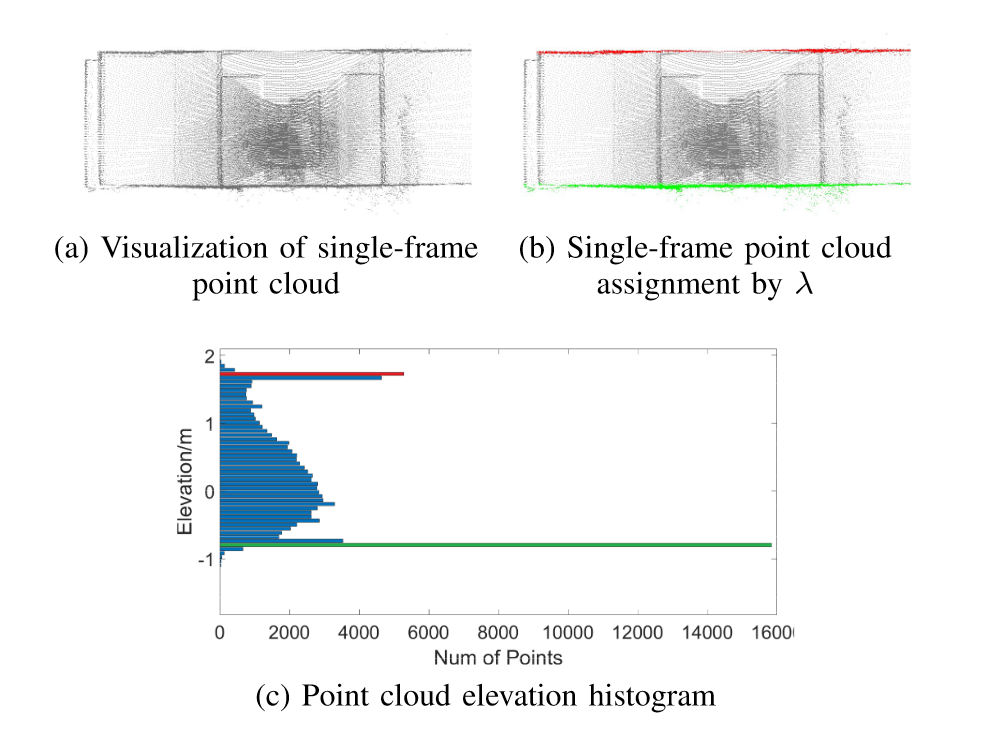
估计 \(h_{floor},h_{ceiling}\) 的主要原因是,在 MC-Dropout 估计不确定度时,天花板和地面的点距离传感器较远,容易得到较低的置信度,但对于室内场景这些点至关重要。因此对于不同的高度采用不同的系数 \(\lambda(h)\) ,再和方差相乘得到置信度。
评价指标
RMSE、MAR、z RMSE(垂直方向上的误差),以及应用到 SLAM 算法中的评估结果(Mean、RMSE、SSE、STD、最大漂移和相对误差)。
结论
MC-Dropout 或其它删除不确定点的操作有利于 SLAM 的结果更稳定。
TULIP: Transformer for Upsampling of LiDAR Point Clouds
暂时没有开源。其中的实验和结论值得学习。
方法
网络建立在 Swin-Unet 基础上,其中主要使用了 Swin Transformer 块。
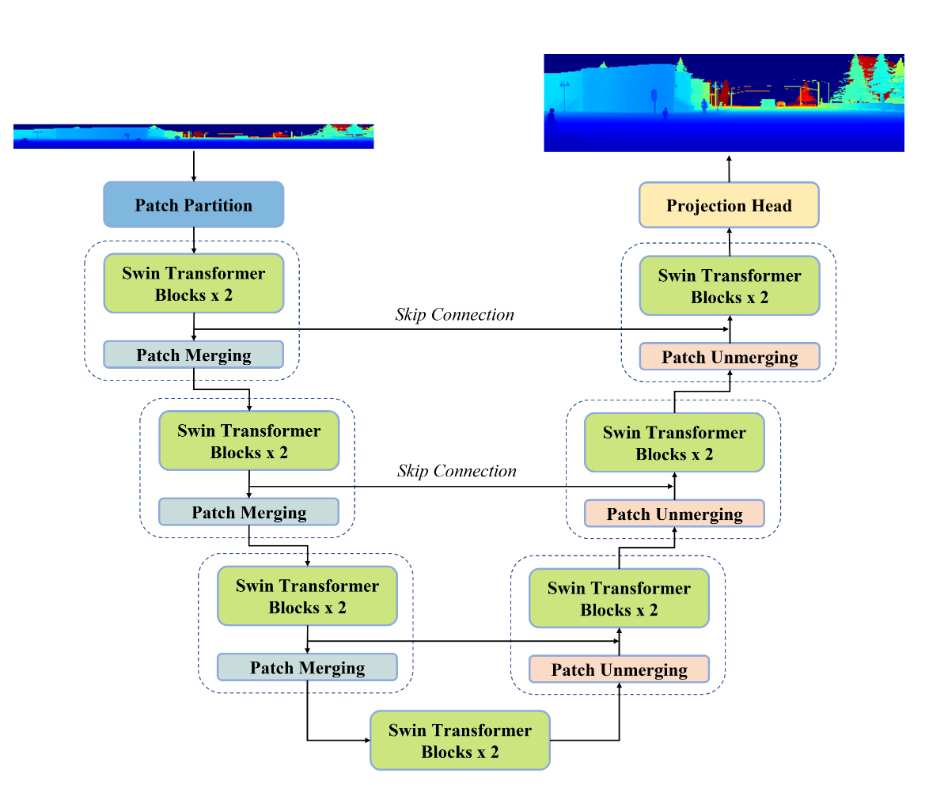
SWIN-Transformer
总结
目前主要的问题包括:
- 现有方法将高分辨率点云下采样,然后进行监督训练,但这意味着无法准确地上采样到更高的分辨率。而使用虚拟数据的方法很难泛化到复杂的真实数据;
- 由于训练数据中大量存在平面特征,往往将物体表面也拟合成平面;
- 对于生成的噪声没有合适的约束,容易在非表面区域生成不合理的点。
