HorizonDrive:长时序自动驾驶世界模型
在地平线的这段时间,我参与研发一个自驾世界模型:目标是能够接受动静态控制、实时地生成视频,并在与 planner 的持续交互下生成稳定的、具备几何一致性的高质量画面。
最近的阶段性实验在内部数据上证明了方法的有效性。我们遂将其在学术数据集上进行评估,整理成了一篇论文,也就是 HorizonDrive。与近期的相关工作相比,我们更深入地探索了如何优化现有的Self-Forcing蒸馏效果,形成了一些有价值的思考。
简单来说,HorizonDrive 不依赖 3D 或 Memory 模块,其核心是通过增强教师自身的抗误差能力,真正意义上为学生模型提供长程、可靠的监督,从而实现分钟级的自回归生成、支持鲁棒的闭环仿真。
这篇博客将简单记录我们的研发过程,并探讨一些未来可能的方向。
解决误差累积问题,不一定从学生出发
起初,我们只有一个从wan2.1 1.3B转化而来的可控生成模型。它能够根据不同长度的条件帧,生成符合控制信号(hd map/bounding box/action)的自驾场景,并适应多种分辨率。
闭环仿真需要多轮交互。因此我们简单测试了该模型的rollout能力,发现其在4~5轮次续写之后,就会发生剧烈的画面崩坏。这也是这一年来自回归生成被讨论最多的一点。
一个有趣的事实是:当时我们需要交付一个业务模型,为了避免过多的开发量,并没有马上尝试Self-Forcing这类蒸馏方法。然而正是因为我们专注于如何让教师模型具备rollout能力,才有了后面的发现。
实际上,鲜少有工作提到如何增强多步Diffusion模型的抗误差能力,自Self-Forcing以来,大家都将重心转移到了最后的蒸馏阶段,希望在学生侧解决误差累积问题。
在华为实习的时候,我在Cosmos上复现过Stable Video Infinity——通过在条件帧上增加单步推理得到的模拟误差,提升模型处理误差的能力,后来的Matrix-Game 3.0也采取了类似的方式。但做完当时的实验后,我已经意识到这种模拟误差的方法(例如Helios)上限都很低。尤其在自动驾驶场景中,几何误差占据了主导,轻微的噪声扰动不足以模拟真实场景的多样性。
另一方面,受限于巨大的计算开销和训练目标错位,Self-Forcing这种在线rollout策略对于教师模型是不切实际的。教师模型要如何高效地rollout?最后又如何用Diffusion Loss更新?这些问题我们都有尝试去解决,但收效甚微。
于是我们开始探索离线方法:先让模型rollout出一系列样本,和真值形成时间对齐的匹配对。然后在训练过程中,直接将条件帧替换成模型生成的带误差帧。由于训练目标本身的不连续性,这样训出来的模型会生成跳变的画面,但质量能够保持平稳。这也是我们预期内的结果。
最终问题聚焦在了如何保住模型的连续性能力。我们做了一个简单的实验:在条件帧和待预测帧的交界处,通过一个线性的渐变连接两者,这样既让模型看到了自己的误差,也让训练目标能够接近GT的质量。
这个做法直接奏效了。我们发现这种平滑过渡实际上给模型提供了一个暗示:前后相邻的latent不应该有过大的距离。训练出来的模型能够保证时序一致性,同时支持十余次rollout展开。
这也就是我们论文中最终采用的办法,我们称之为Scheduled Rollout Recovery(SRR)。
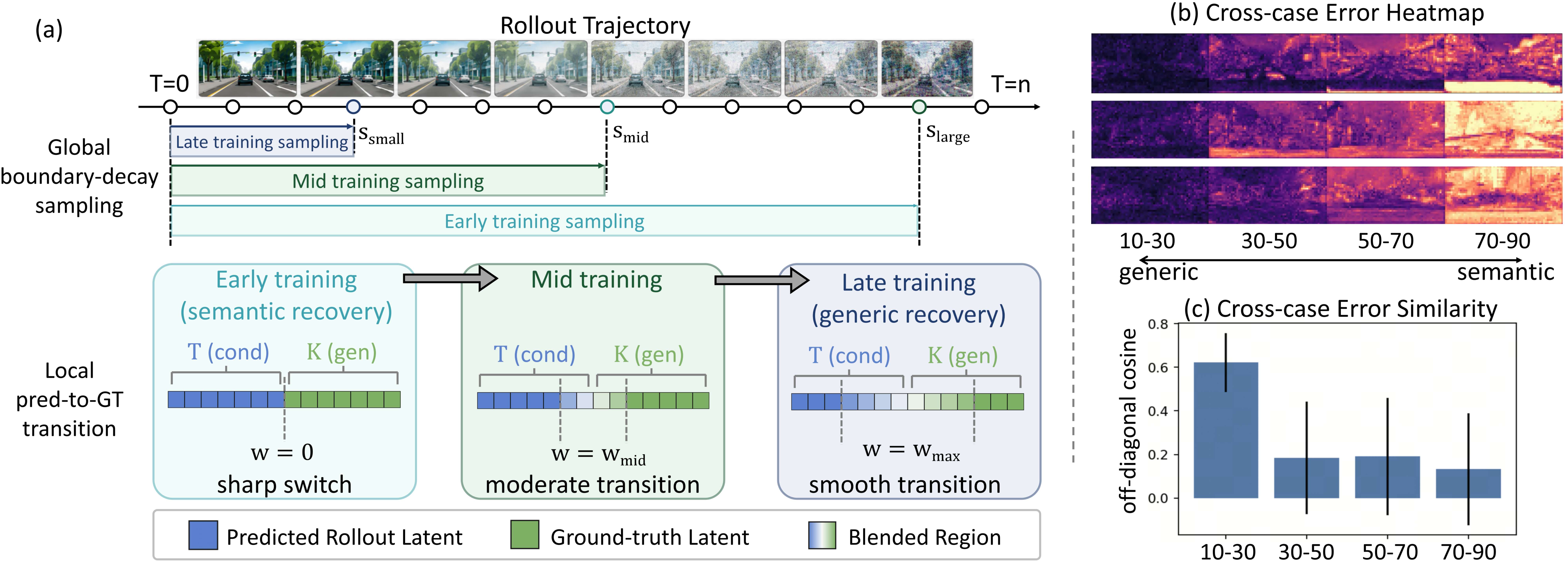
此外,我们还有两个观察:
不连续修复比连续修复更容易。如果只追求下一段画面好看,模型可以直接生成一个新的合理场景,这使得画面质量不会退化。所以 SRR 通过逐步增大的blending窗口,让模型从易到难地学习修复,提高了训练稳定性。
rollout 越往后,误差越带有场景语义。早期误差在不同场景中可能很相似,但随着生成持续进行,误差会越来越依赖具体道路、车辆关系和运动状态。让 teacher 在这种误差上训练,才能真正建模误差修复和场景的耦合关系,让误差从“模拟”走向“真实”。对此我们也同样采用了类似的阶段性学习:在训练初期构建更长的误差数据,提升模型的鲁棒性;在训练后期则构建更短的数据,保障模型的连续性。
三阶段训练范式:走向自动驾驶世界模型
基于SRR,我们很自然地引出了完整的训练框架,可以简单总结为三个步骤:
- 自动驾驶控制信号注入;
- 教师模型抗误差能力提升;
- 长时序DMD训练。
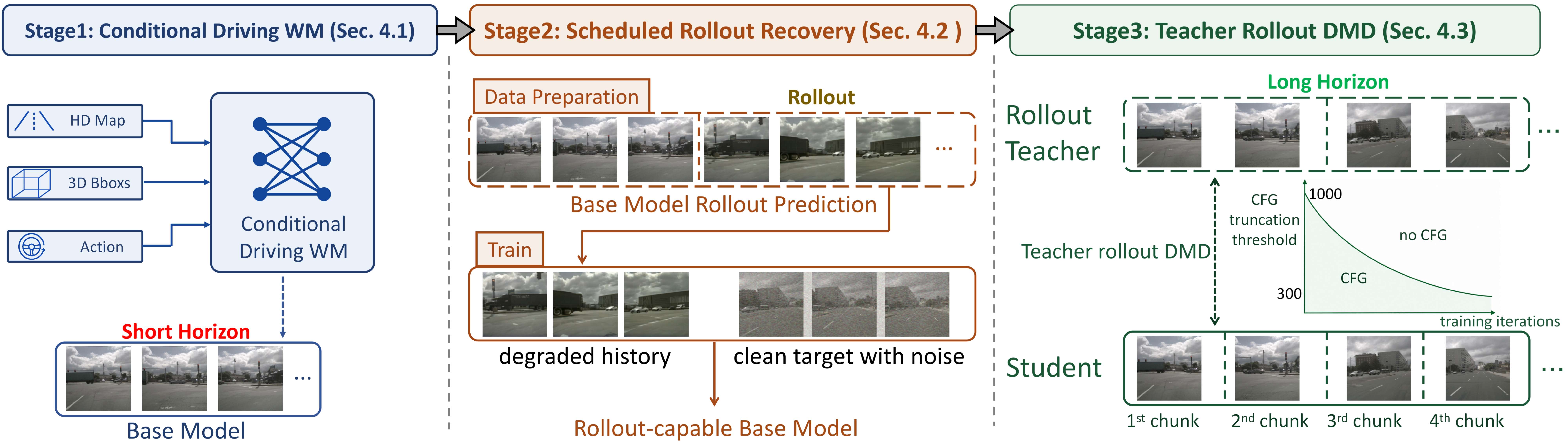
在最后一步蒸馏中,我们发现教师模型的增强能够带来超出预期的增益。一方面,学生的初始化更好,给DMD提供了良好的起点;另一方面,教师的监督信号不会因为学生rollout超出教师长度就失效,而是能够在远超教师长度时依然保持可靠。
我们将这一阶段直白地命名为Teacher Rollout DMD(TRD):学生和教师一起rollout,学生窗口短,教师窗口长。其更强的延展性和更低的参数量,与现有依赖 Wan 14B 作为教师模型的方法形成了鲜明的对比。有界显存下,TRD 能够近乎无限放大教师监督的长度,提升最终学生的长时序能力。
同时提升视觉质量和几何精度
我们在 nuScenes 上对比了代表性的长时序 baseline,HorizonDrive 在视觉指标(FID、FVD、Vbench)和几何指标(ARE、DTW)上都显著领先于基线。
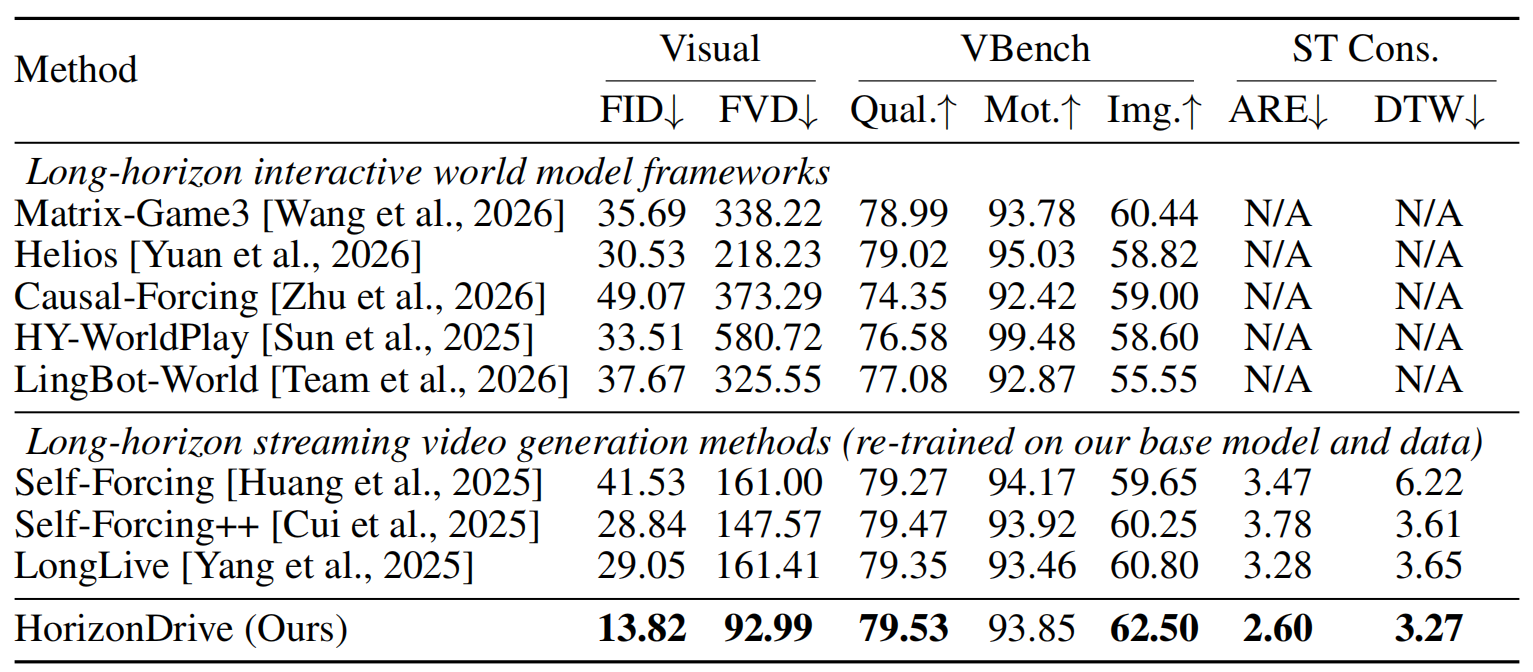
论文中的定性对比则更加直接地展示了 HorizonDrive 在几何结构和画面质量上的双重优势:

更多的效果参见我们的项目主页,包括nuScenes上20s、自建数据集上30s以及一分钟的长视频结果。
写在最后
回顾整个研究,HorizonDrive 最大的特点还是它与现有方法的路线差异:仅依赖模型内在的抗误差能力,实现稳定的长视频生成质量和几何一致性。它证明了模型可以在没有显式约束的情况下,自由地行驶在真实的街区和车流中。对自动驾驶世界模型来说,这可能是一条更干净、也更容易 scaling 的路线。
但未来肯定不止于此。缺少外部先验的情况下,模型始终有点像盲人走路,走一步看一步的生成模式是不可能完全解决所有误差的。我们希望将在这件事做到更极致,让闭环仿真彻底告别视频生成的幻觉。
从方法论上来说,HorizonDrive 和现有的外部增强模块都不冲突,一个提供外在约束,一个提供内在能力。因此合适的先验和简洁的注入方式可能是值得探索的方向。
我也非常期待这样的范式能够被进一步推广,提升其它相似任务的自回归生成效果。以上。