点云深度学习基础
点云上采样是我的第一个科研方向,为此调研过一系列点云深度学习相关的文章。之前每一篇都做了笔记放在网页上,现将其全部汇总一起,可作为点云深度学习的简单入门资料。
PointNet
论文:PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
一、摘要
点云是一类重要的几何数据结构。由于其形式不规则,大多数研究人员将其转换为规则的 3D 体素网格或图像集合来处理。然而这会使数据不必要地庞大。该论文设计了一种直接作用于点云数据的新型神经网络 PointNet,它很好地遵从了输入点的排列不变性,并为从对象分类、部分分割到场景语义解析等应用场景提供统一的架构。PointNet 虽然简单,但展现出了很好的效果。
二、相关工作
3D 深度学习方面,在此论文之前有很多形式出现:
- Volumetric CNNs:最早将 3D 卷积神经网络应用于体素化点云,但由于数据稀疏性和 3D 卷积的计算成本,受到分辨率的限制;
- Multiview CNNs:多视图 CNN 将 3D 点云或形状渲染成 2D 图像,然后应用 2D CNN 对其进行分类。然而将这种方法扩展到场景理解过其它 3D 任务并非易事;
- Spectral CNNs:这种卷积网络在网格点云的频率域上进行,但仅适用于具有规则结构的网格,难以应用于更加复杂和不规则的形状;
- Feature-based DNNs:通过提取传统形状特征将 3D 数据转换为向量,再利用全连接网络对形状分类,但受到特征本身表达能力的限制;
这些方法都不能够直接处理无序点集,而是在尝试将点云转换为序列形式,以便用熟悉的卷积网络来操作,但同时面临计算复杂度等问题。
三、问题陈述
定义点云为一组 3D 点 \(\{ P_i|i=1,\dots,n \}\) ,其中 \(P_i\) 是包含 \((x,y,z)\) 和额外特征通道(如颜色、法线等)的向量,在论文中仅适用 \((x,y,z)\) 坐标。对于分类问题,输入点云可能是单体,也可能是从场景中预先分割得到。PointNet++ 为 \(k\) 个候选类别输出 \(k\) 个分数;对于分割问题,任务可能是从单体中分割出不同的结构,也可能是从三维场景中分割出不同的物体。若共有 \(n\) 个点,\(m\) 个类,则输出 \(n\times m\) 个分数,表示每个点属于每个类的概率,从而进行分割。
四、具体方法
\(\mathbb{R} ^n\) 空间中点集的性质
我们的输入是来自欧几里德空间的点的子集。它具有三个主要属性:
- 无序性。与图像中的像素阵列或体积网格中的体素阵列不同,点云是一组没有特定顺序的点。换句话说,一个使用 N 个 3D 点集的网络需要对 N ! 种输入点排列具有不变性;
- 点之间的关联性。这些点来自具有距离度量的空间。这意味着点不是孤立的,相邻的点形成一个有意义的子集。因此,该模型需要能够从附近的点捕获局部结构,以及局部结构之间的组合相互作用;
- 变换下的不变性。作为一个几何对象,点集的学习表示应该对某些变换是不变的,如旋转和平移。
PointNet 架构
网络具有三个关键模块:作为对称函数的最大池化层,用于聚合来自所有点的信息、局部和全局信息组合结构,以及两个对齐输入点和点特征的联合对齐网络。下面的单独段落中将讨论这些设计选择背后的原因。
无序输入的对称函数
为了解决无序性问题,论文给出了三种策略:
- 引入一种规范的排序方式,但稳定的排序方式难以确定,且易受噪声的影响;
- 把点云看作一个序列信号,并通过随机排列的方式训练 RNN 以驱使输出结果相同,但这种方法随着点云数量增长失去可行性;
- 利用对称函数聚合来自每个点的信息。所谓聚合信息,即将 \(n\) 个向量作为输入而产生一个对输入顺序不变的新向量。例如 \(1+2+3 = 2+3 +1\) 。显然这种方法是较为合适的。
定义函数 \(h:\mathbb{R} ^N \rightarrow
\mathbb{R} ^K\) ,用于对每个点进行处理;定义对称函数 $g:_{n} $
,聚合处理结果;则由输入到输出的一般函数 $f:2^{ ^N} $ 定义为:
\[
f(\{x_1,\dots,x_n\}) \approx g(h(x_1),\dots ,h(x_n))
\] 在实践中,论文采用多层感知器(MLP)来近似 \(h\),利用最大池化函数来近似 \(g\) 函数。
本地和全局信息聚合
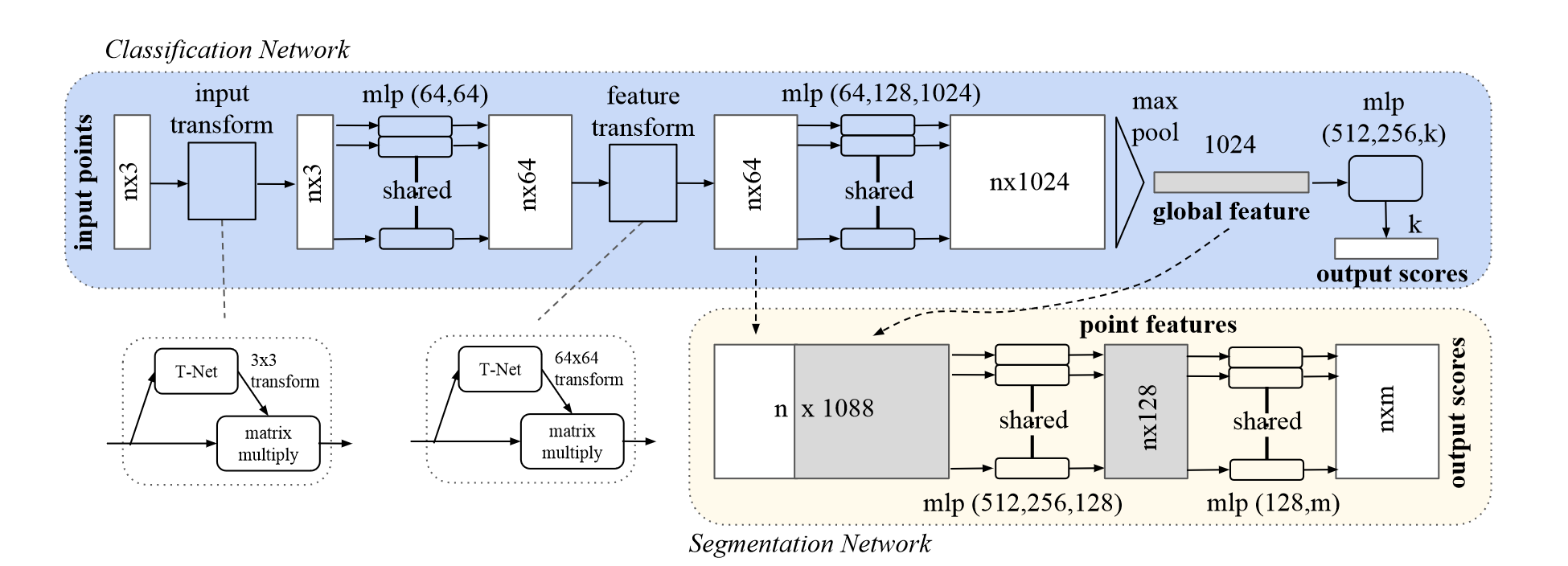
对于分割任务,需要结合本地信息和局部信息。论文采用了简单高效的办法:将学习得到的全局特征和局部特征直接连接在一起,如上图所示。然后再重新提取每个点的特征,从而使得每个点的特征同时包含局部和全局信息。再利用新的组合特征训练几个 MLP ,即可实现每个点的类别判断,也就是分割;若要对单体点云进行识别分类,则直接利用全局特征训练。
联合对齐网络
为了使特征具有旋转平移不变性,论文引入了一种迷你网络 T-net 来直接预测仿射变换矩阵,并将该变换直接应用于原始输入。同样地,特征也需要引入旋转不变性,因此对点特征也可以训练一个对齐网络。
关于 T-net 的结构,其相当于小型的 PointNet,利用最大池化得到全局特征,再利用 MLP 得到 \(3\times 3\) 的转换矩阵。由于特征空间维数较大,增大了优化的难度,因此在 softmax 训练损失的基础上,添加了一个正则化项,用来将特征变换矩阵约束为近似正交矩阵: \[ L_{reg}=\| I-AA^T \|^2_F \] 其中 \(A\) 是由迷你网络预测得到的旋转矩阵。正则项使得优化更稳定,性能更优。
五、总结
为了直接针对点集进行处理,pointnet 的主要思想就是通过池化来解决无序性,通过 MLP 来扩大和缩放特征尺寸。同时为了引入旋转不变性,将点云坐标(或特征)对齐,使用了 T-net 来预测旋转矩阵。
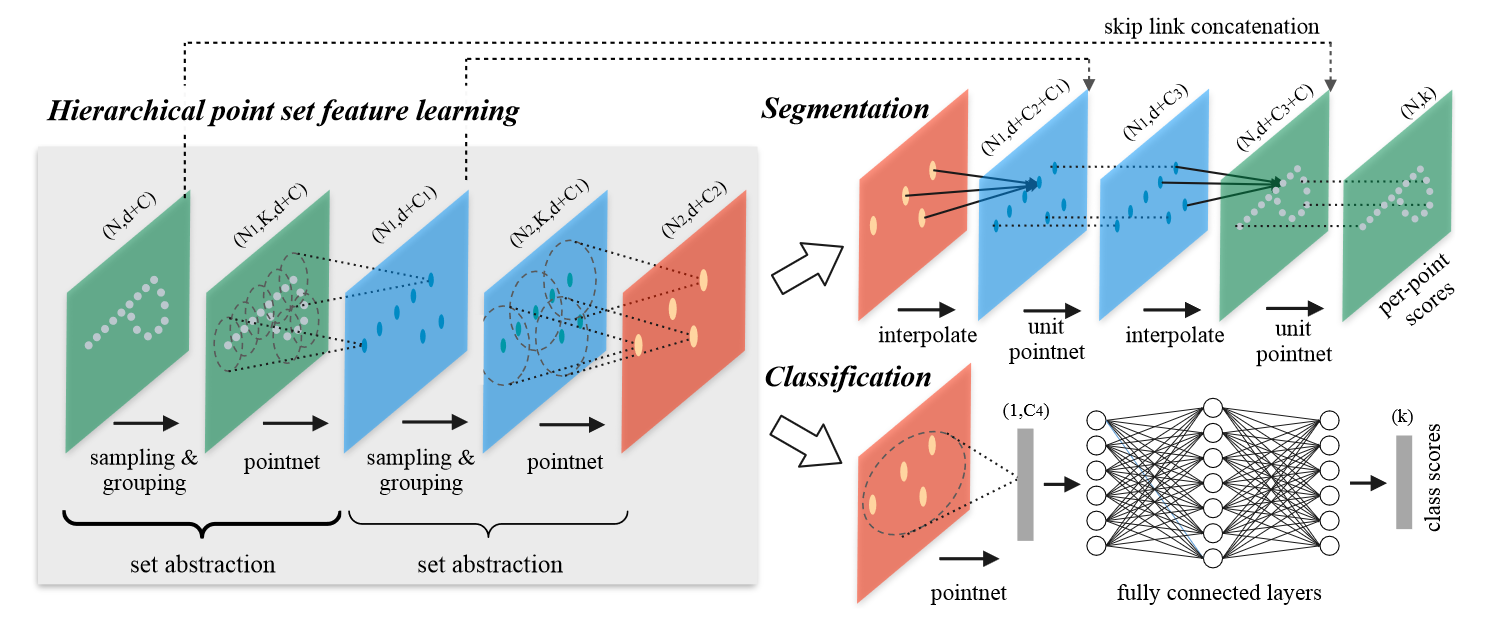
PointNet++
论文:PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
一、摘要及引言
PointNet 是直接处理点集的开创性工作,其基本思想是学习每个点的空间编码,然后将所有单个点特征聚合为全局点云特征。但 PointNet 只对单个点编码,无法捕获局部特征。因此引入了分层神经网络 PointNet++ ,通过以分层方式处理点集的方法来获取不同尺度下的点集特征。
二、问题陈述
假设 \(\mathcal{X} = (M, d)\) 是一个离散度量空间,其度量继承自欧氏空间 \(\mathbb{R}^n\),其中 \(M \subseteq \mathbb{R}^n\) 是点集,\(d\) 是距离度量。此外,环境欧氏空间中 \(M\) 的密度可能并非处处一致。我们感兴趣的是学习将 \(\mathcal{X}\) 作为输入(连同每个点的附加特征)的集合函数 \(f\) 并产生语义兴趣重新分级 \(\mathcal{X}\) 的信息。和 PointNet 一样,这样的 \(f\) 可以是将标签分配给 \(\mathcal{X}\) 的分类函数,也可以是将标签分配给 \(M\) 的每个成员的分割函数。
三、方法
PointNet 回顾
对于无序点集 \(\{x_1,\dots,x_n\}\) ,定义集合函数 \(f:\mathcal{X}\rightarrow\mathbb{R}\) 将点集映射为向量: \[ f(x_1,\dots,x_n)=\gamma\left( \underset{i=1,\dots,n}{\max}\{h(x_i)\} \right) \] 其中 \(\gamma\) 和 \(h\) 通常为多层感知器。PointNet 论文中已经证明 \(f\) 可以逼近任何一个连续集合函数,且对输入点排列不变。但 PointNet 缺乏捕捉到不同尺度的本地特征的能力。
分层点集特征学习
PointNet++ 的层次结构由许多 SA 层(Set Abstraction Levels)组成。SA 层由三个关键层组成:采样(Sampling)层、组合(Grouping)层和 PointNet 层。
抽象层次的输入矩阵大小为 \(N\times(d+C)\) ,表示 \(N\) 个具有 \(d\) 维坐标和 \(C\) 维点特征的点;输出矩阵大小为 \(N'\times(d+C')\) ,表示 \(N'\) 个具有 \(d\) 维坐标和 \(C'\) 维点特征(以总结局部上下文)的子采样点。
采样层
给定输入点 \(\{x_1,x_2,\dots,x_n\}\) ,利用迭代最远点采样(FPS)来选择点的子集 \(\{x_{i_1},x_{i_2},\dots,x_{i_m}\}\) ,使得 \(x_{i_j}\) 是剩余点中距离点集 \(\{x_{i_1},\dots,x_{i_{j-1}}\}\) 最远的点。论文原话虽然凝练但是略微抽象,这里详细阐述一下 FPS 算法的步骤:
- 选定第 \(i\) 个点为初始点,记作 \(x_{i_1}\) ,此时候选集为 \(x_{i_1}\) ;
- 定义点 \(x_k\) 到点集 \(X\) 的距离为 \(\min(\left\|x_k-x \right\|_2)(x\in X)\) ,即到点集中所有点距离的最小值;
- 找到剩余点中距离候选集最远的点,纳入到候选集中;
- 重复步骤 3,直到点数达到设定值。
其中距离的定义一般采用欧式距离,也可以采用测地线距离;初始点随机选择,也可以选择距离点云重心的最远点,使得结果没有随机性。FPS 算法和泊松盘采样很类似,但泊松盘采样提供了更多的随机性,并且对点与点之间的距离要求更宽松。另外,FPS 算法不需要任何参数,应该是更方便可靠的。
采样层得到了 \(N'\) 个采样点,这些点将被用来构成局部特征。
组合层
组合层的输入为 \(N\times(d+C)\) 的点集和 \(N'\times d\) 的采样点集合。对于每个采样点,收集其一定半径范围内最近的 \(K\) 个点(\(K\) 是因采样点而异的),这个操作称为 ball query 。与 KNN 相比,ball query 保证了固定的区域尺度。
每个采样点会生成一个 \(K\times(d+C)\) 的矩阵,因此最后组合得到 \(N'\times K\times(d+C)\) 的矩阵。这个矩阵聚合了一系列的局部点集,如果类比到二维图像,则与 CNN 中的感受野类似,只不过 CNN 中只需要简单地滑动卷积核,而点云中稍微麻烦一些。类似地,PointNet++通过多个 SA 层,逐步扩大感受野,从而提取更高层的特征。
PointNet 层
该层的输入为 \(N'\) 个局部区域,每个 \(K\times(d+C)\) 的局部区域将被聚合为一个 \((d+C')\) 的局部特征向量,组合得到 \(N'\times(d+C')\) 的矩阵。
具体地,首先将局部区域所有点中心化,即 : \[ x_i^{(j)}=x_i^{(j)}-\hat{x}^{(j)},\mathrm{for}\ i=1,2\dots,K\ \mathrm{and}\ j=1,2,\dots,d \] 然后将相对坐标和点特征一起使用,从而捕获局部区域特征,并且消除平移对局部特征的影响。中心化也可以类比到卷积运算中的卷积核中心,因为卷积操作同样不关心每个点在图像中的绝对位置。
非均匀采样密度下的鲁棒特征学习
如前所述,点集在不同区域的密度不均匀是很常见的。这种不均匀性给点集特征学习带来了重大挑战。在密集数据中学习到的特征可能无法推广到稀疏采样区域。同时,为稀疏点云训练的模型可能无法识别细粒度的局部结构。
理想情况下,我们希望尽可能捕获密集采样区域中的细节,但这在稀疏区域无法做到,因为局部特征可能会因采样不足而失效。在这种情况下,我们应该在附近寻找更大尺度的特征。为了实现这一目标,我们提出了密度自适应 PointNet 层(右图),当输入采样密度发生变化时,它可以学习组合来自不同尺度区域的特征。我们将具有密度自适应 PointNet 层的分层网络称为 PointNet++。
对比 分层点集特征学习 章节所描述的 SA 层,PointNet++中每个 SA 层将提取多个尺度的局部特征,并根据点密度将它们组合,论文提出了两种类型的密度自适应层:MSG 和 MRG 。
多尺度组合(Multi-scale Grouping,MSG)
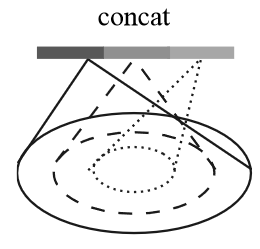 如右图所示,在每个采样点上,用
PointNet
提取不同尺度的特征并将其组合形成多尺度特征。同时为了给网络提供不同密度的输入,采用
random input dropout 方法,随机选取 dropout 概率 \(\theta\in\left[0,p\right] (p\le 1)\)
,以概率 \(\theta\)
丢弃部分输入点,从而提供了稀疏性和不均匀性(随机性)。
如右图所示,在每个采样点上,用
PointNet
提取不同尺度的特征并将其组合形成多尺度特征。同时为了给网络提供不同密度的输入,采用
random input dropout 方法,随机选取 dropout 概率 \(\theta\in\left[0,p\right] (p\le 1)\)
,以概率 \(\theta\)
丢弃部分输入点,从而提供了稀疏性和不均匀性(随机性)。
多分辨率组合(Multi-resolution Grouping,MRG)
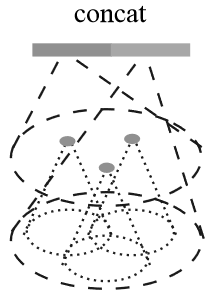 考虑到
MSG
方法计算代价较大,提出一种替代方法:MRG,如图(右)所示。对于每个局部区域的特征
\(L_i\)
,都由两个特征组成:左边特征通过 SA
层得到,右边特征则通过对区域内所有点云利用 PointNet 获取特征(相当于在
SA 层中嵌套了一个 SA 层?)。
考虑到
MSG
方法计算代价较大,提出一种替代方法:MRG,如图(右)所示。对于每个局部区域的特征
\(L_i\)
,都由两个特征组成:左边特征通过 SA
层得到,右边特征则通过对区域内所有点云利用 PointNet 获取特征(相当于在
SA 层中嵌套了一个 SA 层?)。
当局部区域密度较低时,第一个向量往往不如第二个可靠,这时可以提高第二个向量的权重。相反地,局部区域密度较高时,第一个向量提供了更精细的细节特征。
用于点分割的特征传递
SA 层对原始点集进行了下采样,然而在分割任务重我们希望获得所有原始点的点特征(即输入输出矩阵的行数应相等)。一种办法是在每个 SA 层中将所有点都采样为中心点(即去掉了 Sampling 层),但这样会导致计算代价非常大。因此论文给出了另一种方法:特征传播(FP)层(Feature Propagation level)。设 \(N_l\ ,\ N_{l-1}\) 是第 \(l\) 个 SA 层输出和输入的点集大小(\(N_l\le N_{l-1}\)),FP 层通过在 \(N_{l-1}\) 个点的坐标处插入 \(N_l\) 个点的特征值 \(f\) 来实现上采样。具体的插值方法,论文选择了基于 kNN 的反距离加权平均: \[ f^{(j)}(x)=\frac{\sum_{i=1}^kw_i(x)f_i^{(j)}}{\sum_{i=1}^kw_i(x)}\ \ \textrm{where}\ w_i(x)=\frac{1}{d(x,x_j)^p},\ j=1,\dots,C \]
然后将插值得到的特征和来自 SA 层的 \(N_{l-1}\) 个特征连接(skip link)起来,并传递给 unit pointnet 。unit pointnet 论文中没有更多介绍,只说是类似于 \(1\times 1\) 卷积核。由此来看,unit pointnet 应该就是没有池化操作的 pointnet ,因此只是重组了每个点的特征向量,并不会改变点的个数。
重复通过与 SA 层个数相同的 FP 层,即可将输出矩阵行数恢复为 \(N\) ,并且特征长度重组为 \(k\) ,即类别个数,从而达到分割的目的。
四、总结
针对 pointnet 难以获取局部特征的缺陷,pointnet++ 主要做了以下改进:
- 采用多个 SA 层逐步获取多层次的特征信息。其中采样层利用 FPS 算法生成采样点;组合层利用 ball query 算法构成局部区域;pointnet 层提取局部区域特征;
- 采用多个 FP 层进行特征上采样,融合高层特征和底层特征,实现分割任务。利用了反距离加权插值来上采样特征值,利用了 unit pointnet 来提取特征;
- 提出了 MSG 和 MRG 两种方法来应对非均匀采样问题,主要原理是在 SA 层中为采样点生成多尺度的局部信息,并通过 dropout 方法来提供稀疏性和不均匀性。
PU-Net
论文:PU-Net: Point Cloud Upsampling Network
一、摘要
由于数据的稀疏性和不规则性,使用深度网络学习和分析 3D 点云具有挑战性。论文提出了一种数据驱动的点云上采样技术,即 PU-Net ,其关键思想是学习每个点的多级特征,并通过多层卷积单元扩展特征,然后将这些特征重建为上采样点集。网络应用于 patch-level,通过联合损失函数驱使上采样点以均匀的方式分布在隐式表面上。最后论文通过一系列实验展现网络的效果,并阐述了其局限性。
二、相关工作
论文中将点云上采样的方法主要分为两类:基于优化(optimization-based)的方法和基于深度学习(deep-learning-based)的方法。
基于优化的方法
移动最小二乘法(Moving Least Squares, MLS)
参考论文:Computing and Rendering Point Set Surfaces
通过已有点的局部信息估计平滑表面,并将其投影到表面上,可以实现点云的平滑,同时因为描述了表面结构,可以实现上采样和下采样。假设从表面 \(S\) 上获取到点 \(p_i \in \mathbb{R}^3,i\in \{1,2,\dots,N \}\) ,目标是将 \(S\) 附近的点 \(r\) 投影到近似表达 \(p_i\) 的二维表面 \(S_P\) 上。
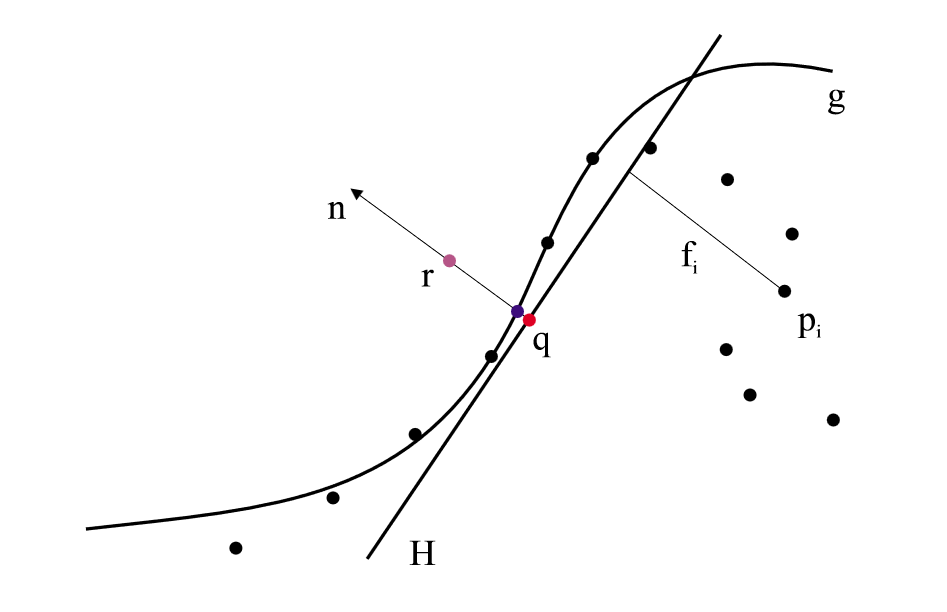
首先找到 \(r\) 的局部参考域(Local Reference Domain) \(H\) ,\(H\) 是一个平面,可以通过其单位法向量 \(n\) 以及原点到平面的距离 \(D\) 共同定义,即 \(H = \{x|\left< n,x \right> - D = 0,x\in\mathbb{R}^3 \}\) 。参考域 \(H\) 通过最小化加权距离平方和得到: \[ \sum_{i=1}^{N}(\left< n,p_i \right>-D)^2\theta\left(\| p_i - q \|\right) \] 其中 \(\theta\) 是一个平滑的单调递减函数,在整个空间上都是正的,如 \(\theta(d)=e^{\frac{d^2}{h^2}}\) 。考虑到点到平面距离同样可以转换到 \(q\) 点上:\((\left< n,p_i \right>-D)^2 = (\left< n,p_i-q \right>)^2\) ,将 \(q\) 点坐标写作 \(r+tn\) ,则式子改写为: \[ \sum_{i=1}^{N}(\left< n,p_i-r-tn \right>)^2\theta\left(\| p_i - r-tn \|\right) \] 函数的因变量为 \(t\) 和 \(n\) ,可以通过非线性最小二乘的方式求得。
然后计算局部图(Local Map),即通过多项式近似来拟合曲面。如上图所示,令 \(f_i\) 为 \(p_i\) 到 \(H\) 的距离,即 \(f_i= n \cdot (p_i-q)\) 。设多项式函数为 \(g\) ,则其系数通过最小化下式得到: \[ \sum_{i=1}^{N}(g(x_i.y_i)-f_i)^2\theta(\| p_i - q \|) \] 这里 \((x_i,y_i)\) 是 \(p_i\) 点投影到 \(H\) 平面的坐标, \(q\) 为原点。总而言之,从 \(H\) 的视角来看,其它点分布在其上下,利用多项式拟合了一个凹凸不平的曲面 \(S_P\) 来接近所有点,其中离原点 \(q\) 越远的点权重越低。
最后进行投影操作。\(r\) 点的投影即为为原 \(g,\mathrm{g}\) 点处的多项式值,即: \[ \mathscr{P}(r)=q + g(0,0)n = r+(t+g(0,0))n \] 该算法涉及到两次最小二乘,其中第一次的相对复杂一些,可能需要一些假设或技巧来求解,这里不展开。
局部最佳投影(Local Optimal Projection, LOP)
参考论文:Parameterization-free Projection for Geometry Reconstruction
MLS 方法假设局部平面可以很好地近似局部几何形状,并不能适用于复杂形状。因此设计一个新的不使用局部方向信息(参考平面或法线)的算子来解决这一问题,也就是 LOP 算子。
问题仍然是一个投影问题:给定数据点集 \(P = \{p_j\}_{j\in J}\subset \mathbb{R}^3\) ,将任意点集 \(X^{(0)}=\{x^{(0)}_i\}_{i\in I}\subset \mathbb{R}^3\) 投影到 \(P\) 上,投影点集为 \(Q = \{q_i\}_{i\in I}\) 。
为了使投影后点逼近 \(P\) 的几何形状,且考虑到距离越远的点作用越弱,定义代价函数 \(E_1\) 表达式为: \[ E_1(X,P,Q)=\sum_{i\in I}\sum_{j\in J}\|x_i-p_j\|\theta(\|q_i-p_j\|) \] 同时为了避免投影后点太靠近彼此,定义代价函数 \(E_2\) 表达式为: \[ E_2(X,Q)=\sum_{i'\in I}\lambda_{i'}\sum_{i\in I \setminus \{i'\}}\eta(\|x_{i'}-q_i \|)\theta(\|q_{i'}-q_i \|) \] 其中 \(\eta(r)\) 同样是一个递减函数,对彼此接近的 \(q_{i}\) 进行惩罚,使得投影后分布均匀。通常为 \(\eta(r)=1/3r^3\) 。 \(\{\lambda_i\}_{i\in I}\) 是一个平衡项,用 \(\Lambda\) 表示。若 \(\Lambda\) 较大,则以形状不近似的代价去追求分布均匀;若 \(\Lambda\) 较小,则以分布不均的代价去追求形状近似。论文在后续对参数的选取做了比较复杂的证明,但实在是看不懂。
小结
MLS 和 LOP 是较为常用的基于优化的方法,但它们假设物体表面为光滑流形,对边缘的还原较差。也有基于边缘感知的方法,但依赖于好的参数;总的来说,基于优化的方法都不是数据驱动的,严重依赖先验知识。
基于深度学习的方法
论文:此前没有专注于点云上采样的神经网络。
三、网络架构
局部区域生成(Patch Extraction)
考虑到上采样需要利用物体的局部几何信息,论文采用了 patch-based 的方式,也就是从物体点云中收集各种形状的局部区域来训练网络。
具体来说,首先从物体表面随机选取 \(M\) 个点,并从每个选择的点开始,沿着表面生长出一个 patch 。并规定在每个 patch 内,任意两点之间的测地线距离小于一定的阈值 \(d\) 。随后,论文使用泊松盘采样(Poisson-disk Sampling),从每个 patch 上随机生成 \(\hat{N}\) 个点作为该 patch 上参考基准(ground truth)点。同时为了利用到局部和全局信息,论文通过改变 \(d\) 的大小来提取不同比例和密度的 patch 。
泊松盘采样
泊松盘采样的目的是从原始点中采样一部分点,使得任意两点间距离都不会太近。泊松盘采样可以用于随机生成一组分布均匀的点,也可以从已有的点中进行采样。下面主要介绍后者的方法。
- 初始化参考点列表:在每个 patch 上初始化一个参考点列表,这个列表最开始为空;
- 选择第一个参考点:在每个 patch 上随机选择一个点作为第一个参考点,并将其添加到参考点列表中;
- 生成新参考点:在距离第一个参考点一定距离范围内,随机生成一个新的参考点,并将其添加到参考点列表中。这个距离范围通常由两个参数决定,一个是最小距离 \(r\) ,表示新生成的点与已有参考点之间的最小距离;另一个是采样次数 \(k\) ,表示在一个点附近最多采样 \(k\) 个点。
- 验证新参考点:为了避免新参考点太接近已有的参考点,需要对新生成的参考点进行验证。如果新参考点与其他参考点之间的距离都大于等于 \(r\) ,则接受新参考点,并继续进行步骤 3 。否则,舍弃新参考点,重新生成一个新的参考点,并重复步骤 4 ,直到找到符合条件的新参考点。
- 重复步骤 3 和 4 ,直到达到预设的参考点数量或者无法再添加新的参考点为止。
泊松盘采样算法是一个计算密集型的过程,因此需要采用高效的算法来实现。通常,可以使用基于网格的算法(例如网格边长为 \(r\) ,则非相邻的网格内两点距离一定大于 \(r\) )或基于随机抽样的算法来实现泊松盘采样。
点特征嵌入(Point Feature Embedding)
为了从 patch 中学习局部和全局几何上下文,考虑以下两种特征学习策略,它们的优点相互补充。
分层特征学习
论文采用了上文 PointNet++ 中提出的层级特征学习机制作为网络的最前端,从而在不同尺度上提取点云的局部和全局特征。同时因为点云上采样需要涉及到更多的局部上下文,特地在每个级别中使用了相对较小的分组半径(grouping radius)。关于分层特征学习以及 PointNet++ 相关内容,可以参考上文 PointNet 和 PointNet++ 两节。
多级特征聚合
网络中较低层对应较小尺度的局部特征,较高层对应较大尺度的局部特征。在 pointnet++ 中采用了 skip link 来联合多级特征,但论文在实验中发现“这种自上而下的传播”方法不适合上采样问题(但似乎没有给出具体原因)。因此论文给出的方法是直接组合来自不同级别的特征,并让网络学习每个级别的重要性。
如下图的 Point Feature Embedding 部分,补丁的输入为大小 \((N,3)\) 的坐标矩阵,在分层特征提取的过程中不断被下采样,同时特征被提取为不同的尺寸。为了融合不同特征,将每一层的特征上采样(反距离加权插值)为行数为 \(N\) 的特征矩阵,并利用 \(1\times 1\) 卷积将特征长度减少为 \(C\) ,最后直接拼接起来得到嵌入点特征 \(f\) 。
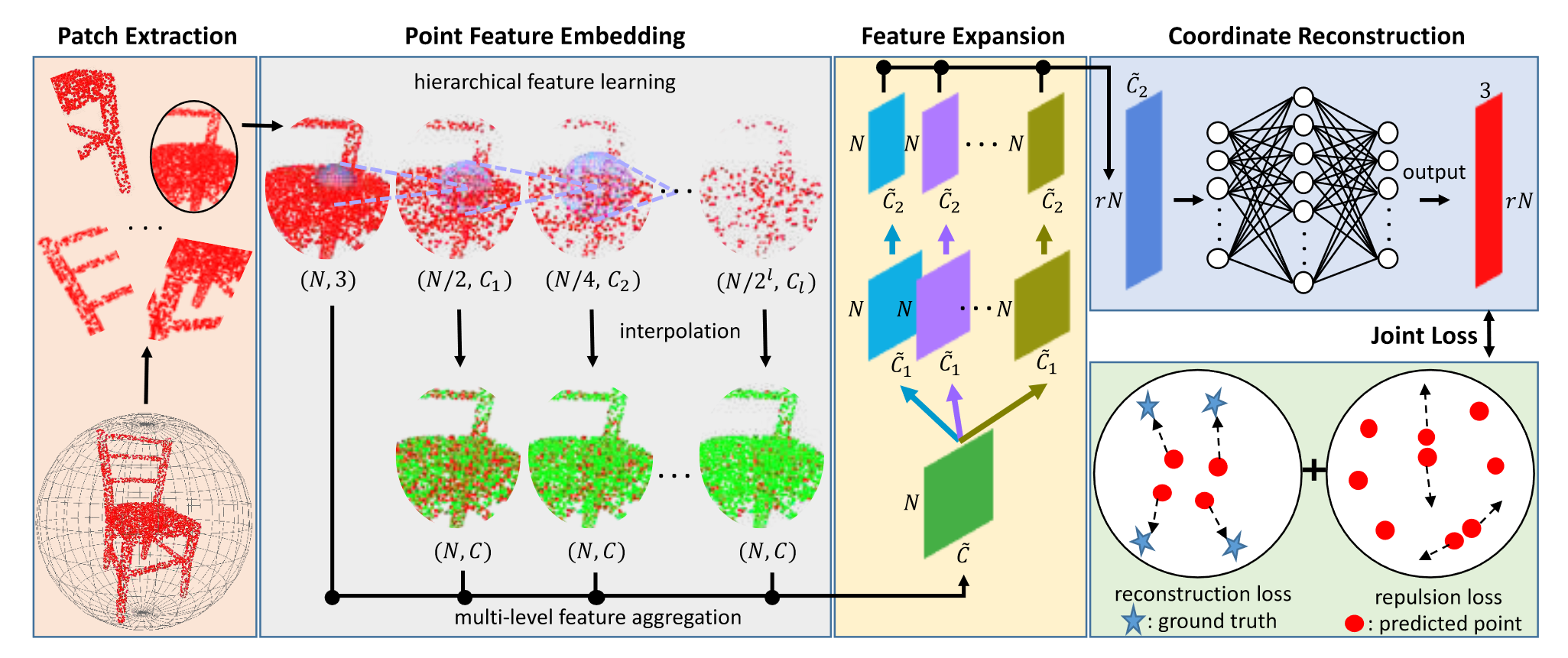
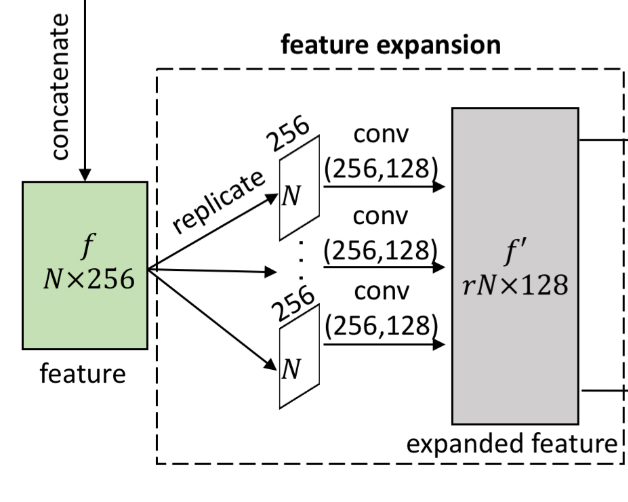
特征扩展(Feature Expansion)
在点特征嵌入组件之后,论文扩展了特征空间中的特征数量,从而扩大了点的数量,达到上采样的目的。假设 \(f\) 的维度为 \(N\times \widetilde{C}\) ,\(N\)为输入点数, \(\widetilde{C}\) 为嵌入特征的特征维度。特征扩展操作将输出维度为 \(rN \times \widetilde{C}_2\) 的特征 \(f'\),其中 \(r\) 是上采样率,\(\widetilde{C}_2\) 是新的特征维度。本质上,这类似于图像相关任务中的特征上采样,在图像中可以通过反卷积(也称为转置卷积)或插值来完成。然而,由于点的不规则性和无序性,将这些操作应用于点云并非易事。因此,论文提出了一种基于亚像素卷积层的有效特征扩展操作。该操作可以表示为: \[ f'=\mathcal{RS}(\ [\ \mathcal{C}^2_1(\mathcal{C}^1_1(f)),\dots,\mathcal{C}^2_r(\mathcal{C}^1_r(f))\ ]\ ) \] 其中 \(\mathcal{C}_{i}^1\) 和 \(\mathcal{C}_{i}^2\) 是两个独立的 \(1\times1\) 卷积,\(\mathcal{RS}\) 是一个 reshape 操作,将大小为 \(N\times r\widetilde{C}_2\) 的张量转换成大小为 \(rN\times\widetilde{C}_2\) 的张量(以此实现点数的放大)。
论文提到,嵌入特征 \(f\) 已经聚合了来自邻域点的相关信息,因此在特征扩展时无需明确考虑空间信息。同时为了让扩张的特征相关性降低(避免生成的点距离太近),因此在 \(\mathcal{C}_{i}^1\) 的基础上添加了 \(\mathcal{C}_{i}^2\) 。这种特征扩展可以通过对 \(r\) 个特征集应用分离卷积实现(如上图所示),也可以通过计算效率更高的分组卷积来实现。
关于分组卷积的概念,参考了飞浆的文档 。简单来说,普通卷积有 \(C_2\) 个,尺寸为 \(h_1\times w_1\times C_1\) ,将大小为 \(H_1\times W_1\times C_1\) 的输入张量转换为大小为 \(H_2\times W_2\times C_2\) 的输出张量。分组卷积则将原始输入张量分割为 \(g\) 个大小为 \(H_1\times W_1\times \frac{C_1}{g}\) 的张量,对应地,将卷积核尺寸变为 \(h_1\times w_1\times \frac{C_1}{g}\) ,卷积个数变为 \(\frac{C_2}{g}\) ,使得输出尺寸为 \(H_2\times W_2\times \frac{C_2}{g}\) 。最后将 \(g\) 个输出拼接即可。如下图所示:
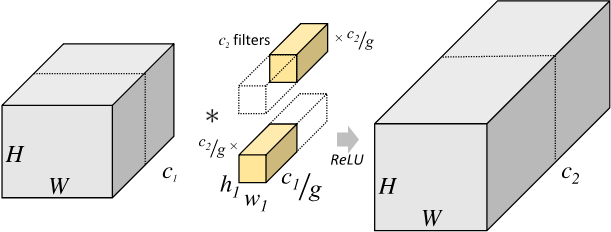
普通卷积的参数量为 \(h_1\times w_1 \times C_1\times C_2\) ,而分组卷积的参数量缩减为: \[ h_1\times w_1\times \frac{C_1}{g} \times \frac{C_2}{g}\times g=h_1\times w_1 \times C_1\times C_2\times\frac{1}{g} \] 针对特征扩展问题,则将 \(\widetilde{C}\) 视作通道数目,将其进行分组从而实现加速。
坐标重建(Coordinate Reconstruction)
得到 \(rN\times\widetilde{C}_2\) 的张量后,将其重建为坐标值。论文采用了一系列全连接层来对每个点的特征回归 3D 坐标,最终输出 \(rN\times3\) 的上采样坐标。
四、端到端训练
训练数据生成
对于一个稀疏的输入点云,实际上有许多可行的输出点分布。因此论文采用了在每个训练时期以 \(r\) 的下采样率从 ground truth 点集中随机采样的方法,生成一些列输入点集,从而为给定的稀疏输入点分布模拟出来许多可行的输出点分布(不应该是输入点分布么?)。同时该方法可以进一步扩大训练数据集。
联合损失函数
为了鼓励生成的点以更均匀的方式分布在底层对象表面上,论文提出了结合重建损失(Reconstruction Loss)和排斥损失(Repulsion Loss)的联合损失函数。
重建损失函数
对于两组点云之间的距离度量方法,主要有 CD(Chamfer Distance)和 EMD(Earth Mover's Distance),下面分别做详细介绍,主要参考 A Point Set Generation Network for 3D Object Reconstruction from a Single Image 这篇文章。
EMD
EMD 也称作“推土机距离”,通过定义“工作量”——即将一个分布搬运到和令一个分布相同所需的搬运量和搬运距离乘积总合——来衡量两组分布之间的相似性。数据的分布经常用直方图来表示,而对于点云,这个定义会简洁一些,目标是找到预测点云 \(S_P\subseteq \mathbb{R}^3\) 和参考基准点 \(S_{gt}\subseteq \mathbb{R}^3\) 之间的一个双向映射 \(\phi\)(既是单射又是满射,也就是一一对应的映射),使每个点与其映射的点之间的距离总和最小,也就是“搬运”的工作量最小即可: \[ L_{rec} = d_{EMD}(S_p,S_{gt})=\underset{\phi:S_p\rightarrow S_{gt}}{\min}\sum_{x_i\in S_p}\|x_i-\phi(x_i) \|_2 \] 虽然概念上简单,但是 EMD 是一个优化问题,运算量比较大,可以通过给每个点分配固定的时间量并在一定错误率内终止来加快运行速度。
CD
CD 也称作“倒角距离”,定义为最近距离的平方和: \[ d_{CD}(S_1,S_2)=\sum_{x\in S_1}\underset{y\in S_2}{\min}\|x-y\|^2_2+\sum_{y\in S_2}\underset{x\in S_1}{\min}\|y-x\|^2_2 \] “由于三角不等式不成立,严格意义上 \(d_{CD}\) 并非距离函数”。关于文章中提到的这点,反例很容易举出。在网上博客大多会找到这样的版本: \[ d_{CD}(S_1,S_2)=\frac{1}{\|S_1\|}\sum_{x\in S_1}\underset{y\in S_2}{\min}\|x-y\|^2_2+\frac{1}{\|S_2\|}\sum_{y\in S_2}\underset{x\in S_1}{\min}\|y-x\|^2_2 \] 这个式子进一步考虑了两个点云数量不同的情况。
除了上述两种度量方式,还有此前在 PCL 笔记里记过的 Hausdorff 距离(点到点集的最小距离的最大值),但显然不太适用于这里。
方法对比
文章中用两种损失函数来计算一系列“平均形状”,从而对两者进行对比分析,如下图所示。

平均形状的具体计算方法没有详细说明,只提到用随机梯度下降法来最小化距离函数。从结果来看,平均形状的点数应该是固定好的,并且有一个合适的初始位置。
观察图中的平均形状,论文给出了以下结论:
- 在第一种和第二种情况下,只有一个连续变化的隐藏变量,即 (a) 中的圆半径和 (b) 中的弧段位置。EMD 粗略地捕获了对应于隐藏变量的平均值的形状。相比之下,CD 会产生一种模糊形状,其几何结构呈飞溅形状;
- 在后两种情况下,存在分类隐藏变量:正方形位于 (c) 的哪个角以及在条形 (d) 旁边是否有圆。CD 将少量的点分布在主体之外的正确位置;而 EMD 则严重扭曲了主体之外的点。
总的来说,EMD 对主体形状的拟合能力更强,而 CD 对总体形状的保持能力更强。论文中采用了 EMD 。
排斥损失(Repulsion Loss)
为了生成更加均匀分布的点,论文设计了排斥损失,表达式为: \[ L_{rep}=\sum_{i=1}^{\hat{N}}\sum_{i'\in K(i)}\eta(\|x_{i'}-x_{i} \|)w(\|x_{i'}-x_{i} \|) \] 其中 \(\hat{N}=rN\) ,是输出点的数量;\(K(i)\) 是点 \(x_i\) 的 \(k\) 近邻点的索引集合;\(\eta\) 称为排斥项,是一个递减函数,用于在两个点距离太近时对其惩罚;\(w(r)=e^{-r^2/h^2}\) ,用于使惩罚项随距离快速衰减。这个表达式以及函数形式的选择参考了局部最佳投影(LOP) 。
联合函数
最终得到联合损失函数如下式,其中 \(\theta\) 表示网络中的参数,\(\alpha\) 用于平衡重建损失和排斥损失,而 \(\beta\) 表示权重的 \(L_2\) 正则化项的乘数,用于降低模型参数值以防止过拟合。 \[ L(\theta)=L_{rec}+\alpha L_{rep}+\beta\|\theta\|^2 \]
五、实验
现在还没跑过实验,先看看论文里咋做的。
数据集
由于点云上采样没有公共基准,我们从 Visionair 存储库中收集了 \(60\) 个不同模型的数据集,范围从光滑的非刚性物体(例如 Bunny)到陡峭的刚性物体(例如 Chair)。其中,我们随机抽取 \(40\) 个进行训练,其余的用于 testing 。我们为每个训练对象裁剪 \(100\) 个补丁,总共使用 \(M = 4000\) 个补丁来训练网络。对于测试对象,我们使用蒙特卡洛随机采样方法在每个对象上采样 \(5000\) 个点作为输入。为了进一步证明我们网络的泛化能力,我们直接在 SHREC15 数据集上测试我们训练有素的网络,该数据集包含来自 \(50\) 个类别的 1200 个形状。具体来说,我们从每个类别中随机选择一个模型进行测试,考虑到每个类别包含 \(24\) 个不同姿势的相似对象。至于 ModelNet40 和 ShapeNet ,我们发现由于网格质量低(例如,孔洞、自相交等),很难从这些对象中提取补丁。因此,我们使用它们进行测试;结果见补充材料。
实施细节
每个补丁的默认点数 \(\hat{N}\) 为 \(4096\),上采样率 \(r\) 为 \(4\)。因此,每个输入补丁有 \(1024\) 个点。为了避免过度拟合,我们通过随机旋转、移动和缩放数据来扩充数据。我们在点特征嵌入组件的四个级别中分别使用分组半径 \(0.05、0.1、0.2\) 和 \(0.3\) ,恢复特征的维数 \(C\) 为 \(64\)。排斥损失中的参数 \(k\) 和 \(h\) 分别设置为 \(5\) 和 \(0.03\) 。平衡权重 \(α\) 和 \(β\) 分别设置为 \(0.01\) 和 \(10^{−5}\) 。实现基于 TensorFlow。为了优化,我们使用 Adam 算法训练网络 \(120\) 个 epoch,mini-batch size 为 \(28\) ,学习率为 \(0.001\) 。训练在 NVIDIA TITAN Xp GPU 上花费了大约 \(4.5\) 小时。
评估指标
为了定量评估输出点集的质量,我们制定了两个指标来衡量输出点与地面真值网格之间的偏差,以及输出点的分布均匀性。
对于表面偏差,我们为每个预测点 \(x_i\) 在网格上找到最近的点 \(x_i\) ,并计算它们之间的距离。然后我们计算所有点的均值和标准差作为我们的指标之一。
对于均匀性指标,我们在物体表面随机放置 \(D\) 个大小相等的圆盘(在我们的实验中 \(D = 9000\))并计算圆盘内点数的标准差。我们进一步归一化每个对象的密度,然后计算测试数据集中所有对象的点集的整体均匀性。因此,我们将磁盘面积百分比 \(p\) 的归一化均匀系数 (NUC) 定义为: \[ \begin{aligned} avg &= \frac{1}{K*D}\sum_{k=1}^K\sum_{i=1}^D\frac{n_i^k}{N^k*p}, \\ NUC &= \sqrt{\frac{1}{K*D}\sum_{k=1}^K\sum_{i=1}^D\left(\frac{n_i^k}{N^k*p}-avg\right)^2}, \end{aligned} \] 其中 \(n_i^k\) 是第 \(k\) 个物体在第 \(i\) 个圆盘内的点数,\(N^k\) 是第 \(k\) 个物体上的总点数,\(K\) 是测试物体的总数,\(p\) 是圆盘面积占总物体表面积的百分比。\(n_i^k/(N^k*p)\) 在均匀分布的理想前提下为 \(1\) ,\(avg\) 表示该值的平均值。\(NUC\) 相当于表达了该值的方差。需要注意的是,我们使用测地距离而不是欧几里得距离来形成圆盘(用测地线距离怎么形成大小相等的圆盘?)。
性能对比
尽管 PU-Net 是第一个专门用于上采样的网络,但还是找了 PointNet 和 PointNet++ 以及 PointNet++(MSG)来作对比,具体方法则是用它们的分割模块来做特征嵌入,然后用重建损失函数训练。但是最后给出的对比表格是用于评价均匀性的 NUC 指标?这是不是不太公平哈哈。剩下的对比和实验就不记录了,大致就是在不同的数据集上测试了一下效果。
六、总结
PU-Net 主要的内容概括如下:
- 在局部区域生成方面,采用了泊松盘采样,提供了均匀性和随机性;
- 在特征嵌入方面,参考了 PointNet++ 中的分层学习,并且采取了更直接的组合方式;
- 在特征扩展方面,利用 \(1\times1\) 卷积对特征上采样,并重组为 \(rN\times \widetilde{C}_2\) 的矩阵;最后对该矩阵进行特征重组,直接得到点坐标;
- 采用了联合损失函数,包括重建损失(EMD)、排斥损失(参考 LOP 方法)以及参数正则化项;
- 通过 NUC 指标评价生成点的均匀性。
关于网络的局限性,论文提到了两方面:
- 网络不是为补全而设计的,因此不能填补大洞和缺失的部分;
- 网络无法为严重欠采样的微小结构添加有意义的点。
同时也指出可以研究更多下采样方法,来生成更多的不规则稀疏数据用于训练。
EC-Net
论文:EC-Net: an Edge-aware Point set Consolidation Network
一、摘要及引言
点云整合(point cloud consolidation)是将点云“按摩”到表面上的过程,去噪、补全、重采样等等都属于其一部分。目前数据驱动方法展现出了很好的性能,但它们忽略了 3D 对象的锐利特征。该论文提出了第一个用于边缘感知整合网络 EC-Net ,其在 PointNet 的启发下,通过将坐标转换为深层特征并进行特征扩展产生更多点。同时论文提出了一种仅适用于点云的 patch 提取方案,以便提取 patch 并在训练和测试阶段共同使用。
此外,为了使得网络具有边缘感知能力,论文将边缘和网格三角形信息同 patch 相关联,通过回归点到边缘的距离以及点坐标来训练网络。更重要的是,论文通过一种新颖的 edge-ware 联合损失函数,可以有效地比较输出点和基准 3D 网格。该损失函数鼓励输出点靠近底层表面和边缘,并更均匀地分布在表面上。
二、方法
训练数据准备
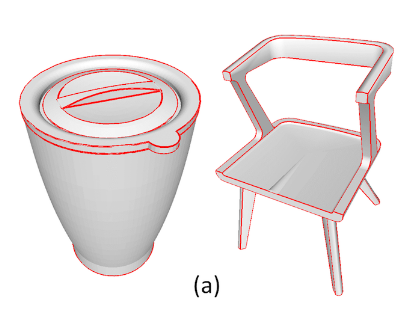
论文从 ShapeNet 和其它在线存储库收集 3D 网格 ,包括简单的 3D 形状、机械零件和椅子等日常用品。并且采用了手动绘制折线的方式来标记网格上的锐利边缘,用于学习点到边缘的距离,如下图所示。
虚拟扫描
为了从 3D 网格获取点云,论文采用了虚拟扫描的方式,具体来说。首先将网格归一化到 \(\left[-1,+1\right]^3\) 单位距离空间里,并在物体周围水平均匀的布置 30 个虚拟相机(视角为 50°),相机距离物体中心两个单位距离,同时随机地扰动相机位置(向上或向下)。之后,通过渲染出网格对象的深度图并为深度值和像素位置添加量化噪声,最后反向投影每个像素得到点云。
这种方式模拟了真实场景里的扫描仪,比一般的下采样方法更加贴合实际。其特点是存在线状的点分布(下图左),离相机越近的平面采样点越密集(下图右),同时具有随机误差。
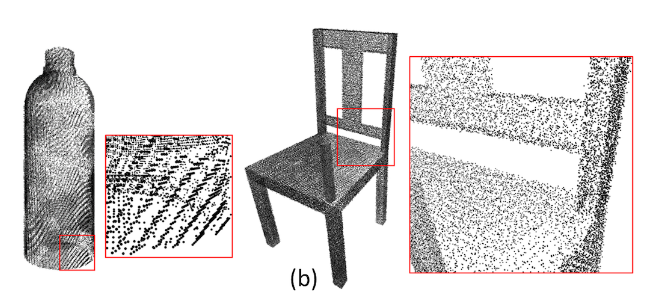
局部区域提取
提取 patch 的依据是测地线距离,因为采用欧氏距离可能导致相邻点位于薄表面的两侧。具体的提取步骤如下:
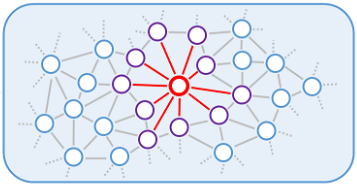 首先将每个点视为节点创建邻接图,图中每个点与其
\(k\) 近邻点(\(k=10\))相连,如右图所示。边权重设置为两点之间的欧氏距离;
首先将每个点视为节点创建邻接图,图中每个点与其
\(k\) 近邻点(\(k=10\))相连,如右图所示。边权重设置为两点之间的欧氏距离;- 随机选择 \(m=100\) 个点作为 patch 的中心点。对于每个选定的点,通过 Dijkstra 算法找到 \(2048\) 个在邻接图上最近的点;
- 在 \(2048\) 个点里随机选取 \(\hat{N}=1024\) 个点,从而引入随机性;
- 将点坐标归一化到单位球内,坐标重心为原点;
- 对于训练所用的 patch ,论文还找到了其附近相关联的网格三角形以及标记的边缘线作为基准信息。
边缘感知的点集整合网络
特征嵌入及扩展
该组件首先使用 PointNet++ 将每个点周围的局部信息映射到 \(D\) 维特征向量中(论文实验取 \(D=256\) )。考虑到 patch 边缘点的局部信息不准确,论文只保留了 \(N = \frac{\hat{N}}{2}\) 个最接近 patch 中心的点对应的特征向量,因此特征嵌入组件的输入为 \(N\times 3\) 的张量。
下图为特征嵌入部分的详细结构,其中在四个级别分别采用了 \(0.1、0.2、0.4、0.6\) 的分组半径来提取局部特征,这四个层次对应的点样本数分别为 \(N,\frac{N}{2},\frac{N}{4},\frac{N}{8}\) 。这里虽然写的是 conv 层,但其实就是 PointNet++ 中的 SA 层。其特征组合方式参考了 PU-Net 。
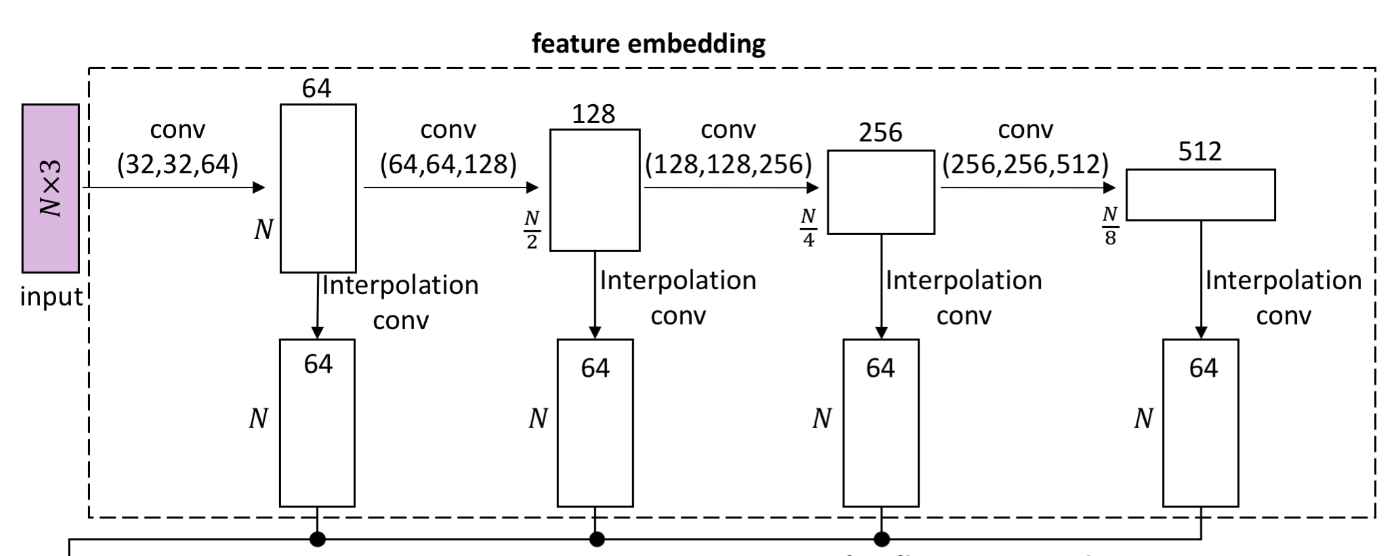
特征扩展部分和 PU-Net 一致,只不过在 PU-Net 中的 \(1\times1\) 卷积,在这里也统一写成了卷积层。特征扩展部分的输出为 \(rN\times128\) 的张量。
边缘距离回归
这一组件将回归每个点到边缘的距离,从而进行边缘点识别。回归距离是点到最近的标记边缘的距离。具体来说,首先通过 MLP 从扩展特征中提取距离特征 \(f_{dist}\) ,然后再通过另一个 MLP 回归点到边缘的距离(但是既然点是无序的,训练样本中的点到边缘距离如何排列?或者随机排列?)。
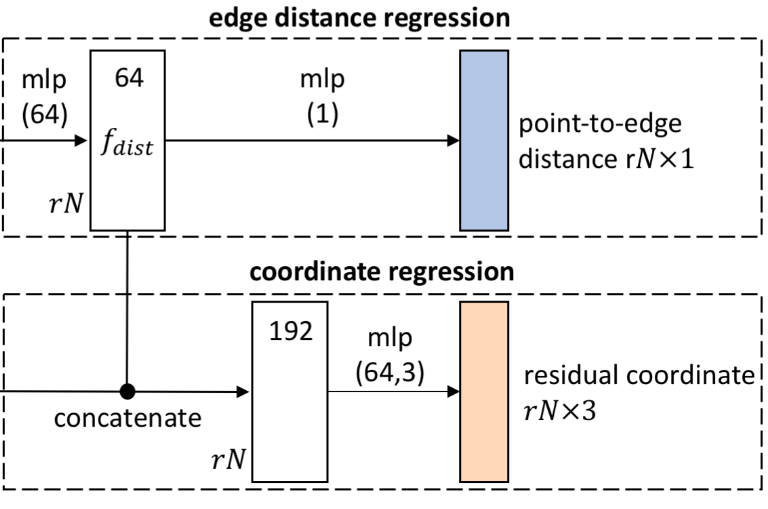
坐标回归
基于边缘距离回归组件中的 \(f_{dist}\) 特征,利用两个 MLP 回归点坐标。在这里论文采用了只回归残差坐标的方式,也就是上采样点相对当前点的偏移值,这样预测值会比较小,有利于网络学习。另外,论文提到除了最后用于回归的 MLP 层,其余所有卷积和 MLP 层后面都接的是 RELU 激活函数。
边缘点识别
记 \(d_i\) 为输出点 \(x_i\) 到边缘的距离,则边缘点集为 \(\mathcal{S}_{\Delta_d}=\{x_i \}_{d_i<\Delta_d}\) 。该组件在训练和测试阶段都会执行。
边缘感知的联合损失函数
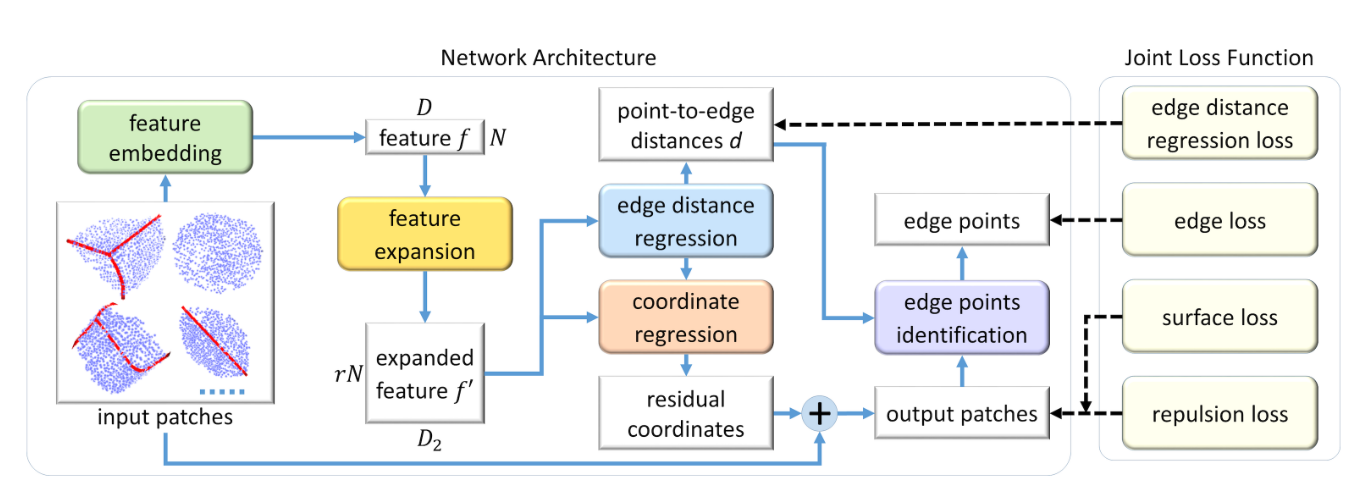
损失函数的设计主要基于以下目标:1)靠近底层物体表面;2)靠近标记边缘;3)均匀分布
表面损失(Surface Loss)
表面损失定义为从每个输出点 \(x_i\) 到与 patch 关联的所有网格三角形 \(T\) 的最短距离: \[ d_T(x_i,T)=\min_{t\in T}d_t(x_i,t), \] 为了计算 \(d_t\) ,需要考虑其中情况,因为三角形 \(t\) 上离 \(x_i\) 最近的点可能位于三角形的顶点、边缘或面内。计算所有输出点的 \(d_T\) ,相加得到表面损失: \[ L_{surf}=\frac{1}{\widetilde{N}}\sum_{1\leq i \leq \widetilde{N}}d_T^2(x_i,T), \] 其中 \(\widetilde{N}=rN\) ,为每个 patch 包含的点数。
边缘损失(Edge Loss)
边缘损失鼓励输出点位于靠近边缘的位置。将与 patch 相关的一组带注释的边缘段记作 \(E\) ,定义边缘损失为从每个边缘点(边缘检测得到)到所有 patch 中的边缘段的最短距离的最小值: \[ d_E(x_i,E)=\min_{e\in E}d_e(x_i,e), \] 其中 \(d_e(xi,e)\) 是边缘点 \(x_i\) 到边段 \(e\in E\) 上任意点的最短距离。将所有边缘点的 \(dE\) 求和,得到边缘损失: \[ L_{edge}=\frac{\sum_{x_i\in \mathcal{S}_{\Delta_d}}d^2_E(x_i,E)}{\left|\mathcal{S}_{\Delta_d} \right|}, \] 总的思路和表面损失一样,只是表面损失针对所有点,边缘损失只针对边缘点。
排斥损失(Repulsion Loss)
排斥损失鼓励输出点更均匀分布。对于输出点 \(x_i,i=1,\dots,\widetilde{N}\) ,排斥损失定义为: \[ L_{repl}=\frac{1}{\widetilde{N}\cdot K}\sum_{1\leq i\leq \widetilde{N}}\ \sum_{i'\in \mathcal{K}(i)}\eta(\left\|x_{i'}-x_i \right\|), \] 其中 \(\mathcal{K}(i)\) 是 \(x_i\) 的 \(K\) 最近邻域的索引集合(论文设 \(K=4\) ),而 \(\eta(r)=\max(0,h^2-r^2)\) 是惩罚函数,两点越近则惩罚项越大。当距离大于 \(h\) 时,则不起作用。
边缘距离回归损失(Edge Distance Regression Loss)
边缘距离回归损失引导网络回归 \(rN\) 个输出点到边缘的距离 \(d\) 。由于并不是每个点都靠近标记的边缘,因此回归损失应在一定距离截断,以免损失过大: \[ L_{regr} = \frac{1}{\widetilde{N}}\sum_{1\leq i \leq \widetilde{N}}\left[\mathcal{T}_b(d_E(x_i,E))-\mathcal{T}_b(d_i) \right]^2 \]
端到端训练
联合损失函数定义为: \[ \mathcal{L}=L_{surf}+L_{repl}+\alpha L_{edge}+\beta L_{regr} \]
实施细节
网络训练
在训练之前,将每个输入补丁归一化到 \([-1, 1]^3\)。然后通过一系列运算符在网络中即时对每个 patch 做数据增强:1)随机旋转;2)在所有维度上随机平移 \(-0.2\) 到 \(0.2\) ;3)随机缩放 \(0.8\) 到 \(1.2\) ;4)添加高斯噪声,参数 \(\sigma\) 设置为补丁边界框大小的 \(0.5\%\);随机调整补丁中点的顺序。
网络推理
这里主要阐述如何通过训练好的网络以 patch-wise (在图像分割中指介于像素和图像级别的区域)方式处理点云。
首先在测试点云中提取点集作为质心,以便使用 2.1 中的过程提取点块。为了使 patch 更均匀地分布在点云上(点云总点数为 \(N_{pt}\) ,patch 点数为 \(N\) ),使用最远点采样法,在测试点云中随机找到 $M = $ 个点,这意味着平均每个点被采样了 \(\beta\) 次,也就是平均每个点出现在 \(\beta\) 个不同的 patch 中。
提取补丁后,将它们输入网络并应用网络生成 3D 坐标和点到边缘的距离,同时进行边缘点识别。与训练阶段的边缘点识别不同,这里设置了一个较小的阈值 \(d =0.05\) 。在训练中则使用较大的 \(d\) ,这是因为训练是一个优化过程,网络需要通过更多的点来学习识别边缘点。
表面重建
首先为网络的输出点构建一个 \(k\) 近邻图。对于边缘点过滤,通过 RANSAC 拟合线段实现;对于表面点过滤,通过边缘停止的方式在 \(k\) 近邻图中找到一小组附近的点,然后使用 PCA 拟合平面来实现。其中边缘停止指的是在到达边缘点时停止广度优先搜索(breath-first growth),这避免了越过边缘将无关点纳入。
重复多次以上步骤,最后通过纳入一些间隙中的原始点来填充边缘点和表面点之间的微小间隔,并通过投掷飞镖法(dart throwing)来添加新点。Dart throwing 是一种随机采样方法,在已有点的基础上,若新点离已有点太近(飞到镖盘内),则重新选取,直至点数达到要求。
为了进一步重建表面,论文采用了 EAR 中的方法对点云进行下采样并计算法线,使用球旋转(ball pivoting)或筛选泊松表面重建(screened Poisson surface reconstruction)来重建表面,并使用双边法线滤波(bilateral normal filtering)清洗生成的网格。这里提到的几个概念似乎属于三维重建,暂且将其相关论文放在这里,以后如果想起来学一下:
- EAR:Edge-aware point set resampling
- ball pivoting:The ballpivoting algorithm for surface reconstruction
- screened Poisson surface reconstruction:Screened poisson surface reconstruction.
- bilateral normal filtering:Bilateral normal filtering for mesh denoising
三、总结
EC-Net 主要内容可以概括如下:
- 为了使网络具有边缘感知能力,通过手动标注的方式在网格上标记边缘;
- 沿用了 PU-Net 中的特征嵌入和特征扩展模块
- 网络同时输出点到边缘距离、边缘点、上采样点,并分别设计了边缘距离损失、边缘损失、排斥损失以及表面损失,得到联合损失函数,用于端到端训练;
- 采用回归残差坐标的方式来得到上采样点坐标
EC-Net 主要存在以下不足:
- 和 PU-Net 一样不具备补全能力;
- 对于严重欠采样的微小结构,网络难以重建其锐利边缘;
- patch 点数固定,导致随着点云密度变化,其大小发生显著改变,难以适应不同规模的结构
DGCNN
近来饱受专业实习折磨,学习方面,有所懈怠
论文:Dynamic Graph CNN for Learning on Point Clouds
一、摘要及引言
在 PointNet、PointNet++ 中,都没有考虑到点云的拓扑结构,即相邻点之间的邻接关系。如果设计一个能够恢复拓扑结构的模型,应当可以增强网络的表示能力。基于这一想法,论文设计了网络模块 EdgeConv 来提取局部邻域信息和潜在的长距离语义特征。
PointNet 通过在局部邻域内独立地处理点,确保了顺序不变性,然而这种独立性一定程度上忽略了点之间的几何关系,因而难以捕获局部特征。而 EdgeConv 并不从点的嵌入中生成点特征,而是生成了描述点与其邻域内点之间关系的边特征,并且对邻域内点的排序具有不变性。同时 EdgeConv 易于嵌入到现有网络中。论文将其集成到 PointNet 中,得到了很好的性能。
二、方法
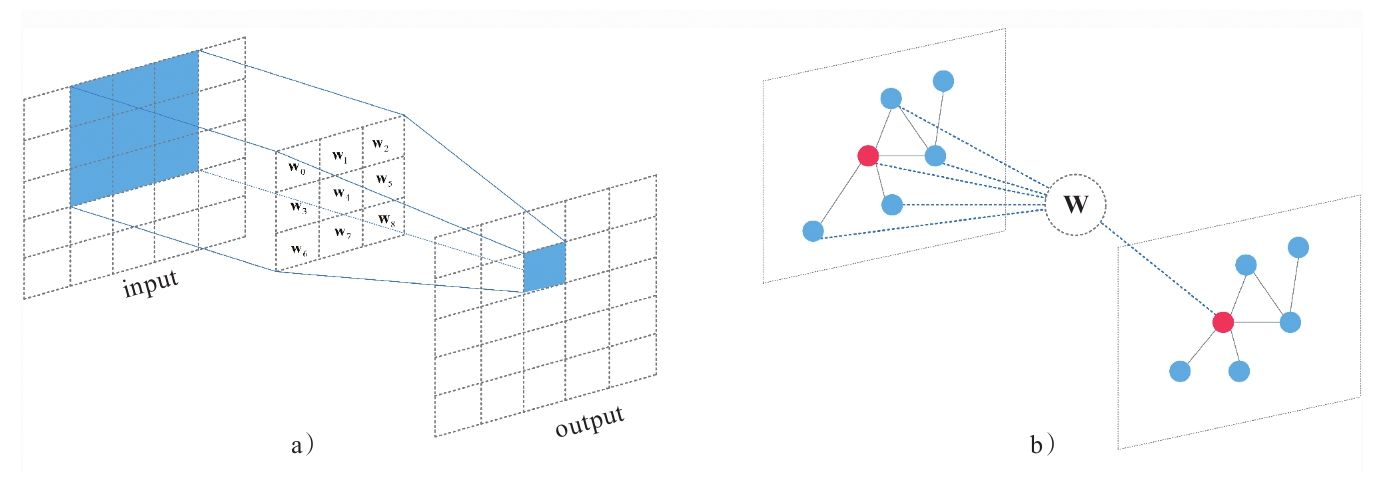
## 图卷积神经网络(Graphic Convolutional Neural Networks,GCN)
由于文章借鉴了图卷积神经网络,因此简单了解了一下图卷积的原理。与 CNN 相比,GCN 主要应用于图数据。也就是节点和边组成的图形。当然图像也是一种特殊的图形,它具有规整的结构。而在特征嵌入方面,两者都是局部连接,并且卷积核权重处处共享。因此 GCN 与 CNN 思想上是基本一致的,只不过应用场景不同。相比之下,GCN 所处理的数据结构会更复杂。
边卷积(Edge Convolution)
基本原理
利用点云能够生成的最简单的图,大概是体素连通性分割里的体素邻接图。但论文所使用的方法有所区别于 GCN,因为它会在每一层根据新的特征序列,重新计算节点的邻接关系。不同于使用空间距离构建的图,这样做意味着图会动态更新,即每个点的 \(k\) 近邻点会在不同层之间发生变化。这使得非局部(non-local)信息能够得到扩散。下面阐述 EdgeConv 具体架构。
将数量为 \(n\) 的 \(F\) 维点云记作 \(\mathbf{X}=\left\{\mathbf{x}_1, \ldots, \mathbf{x}_n\right\} \subseteq \mathbb{R}^F\) ,令 \(F=3\) ,则每个点包含三维坐标 \(\mathbf{x}=(x_i,y_i,z_i)\) ,也可以包含颜色、法线等附加特征。因此 \(F\) 更一般的含义是点特征。
引入一个有向图 \(\mathcal{G}=(\mathcal{V}, \mathcal{E})\) 来表示局部点云结构,其中 \(\mathcal{V}=\{1, \ldots, n\}\) , $ $ ,分别表示节点和边,最简单的 \(\mathcal{G}\) 是 \(k\) 近邻图。图中包含了自环(self-loop),即每个节点也会指向自己。论文定义了以 \(\mathbf{x}_i,\mathbf{x}_j\) 为端点的边缘的特征: \[ \boldsymbol{e}_{i j}=h_{\Theta}\left(\mathbf{x}_i, \mathbf{x}_j\right) \] 其中 \(h_{\boldsymbol{\Theta}}: \mathbb{R}^F \times \mathbb{R}^F \rightarrow \mathbb{R}^{F^{\prime}}\) 是一个非线性函数,\(\Theta\) 为一组可学习优化的参数。
最后,将边缘特征定义为由顶点出发的所有边特征的聚合,聚合方式为对称函数(如求和或者池化),论文里记作一个令人费解的正方形:
\[
\mathbf{x}_i^{\prime}=\underset{j:(i, j) \in \mathcal{E}}{\square}
h_{\Theta}\left(\mathbf{x}_i, \mathbf{x}_j\right)
\] 类比于图像卷积, \(\mathbf{x}_i\) 为中心像点,\(\{\mathbf{x}_j:(i,j)\in\mathcal{E}\}\)
为其邻域内像点。总之,给定一个 \(F\)
维的点云,EdgeConv 将其转换为点数不变的 \(F'\) 维点云。
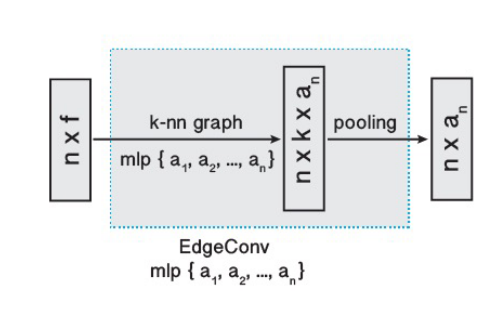
函数的选择
在 EdgeConv 中主要涉及到两个函数的选取:\(h\) 和 \(\square\) 。若 \(\mathbf{x}_1,\dots,\mathbf{x}_n\) 是规则网格上的图像像素,而图 \(\mathcal{G}\) 中表示了每个像素周围固定大小的块的连通性,同时选取边缘函数为 \(\Theta_m\cdot\mathbf{x}_j\) ,聚合操作为求和函数,就得到了标准的卷积操作: \[ x_{i m}^{\prime}=\sum_{j:(i, j) \in \mathcal{E}} \boldsymbol{\theta}_m \cdot \mathbf{x}_j, \] 这个表示的细节就不深究了,个人感觉和一般说的 CNN 不太一样,因为这里似乎对所有邻域内的点都共享了权重。
后面论文列举了很多函数的选取,都比较常规,这里不再赘述。论文所采用的函数如下所示: \[ \left\{\begin{aligned} &e'_{ijm}=\operatorname{ReLU}(\theta_m\cdot(\mathbf{x}_j-\mathbf{x}_i)+\boldsymbol{\phi}_m\cdot\mathbf{x}_i), \\ &x'_{im} =\max\limits_{j:(i,j)\in\mathcal{E}}e'_{ijm}, \end{aligned}\right. \] 不同于 PointNet 中共享的 MLP ,这种特征提取方式考虑了边特征。论文中说可以用共享 MLP 实现,但我还没想明白如何做到的。
动态图更新(Dynamic Graph Update)
论文再次强调了在特征空间中定义图形的优势,即使得感受野和点云直径一样大,并且是稀疏的。用人话说就是不局限在周边点,还会将点云中其它具有相似特征的点纳入到感受野中。在具体实现中,计算了特征空间中的成对距离矩阵,从而为每个点提取最近的 \(k\) 个点。
特性
主要包括置换不变性和平移不变性。置换不变性就不必多说了,平移不变性则来自于 \(h\) 函数。若对点云进行平移操作 \(T\) ,则特征值变为: \[ \begin{aligned} e'_{ijm} &=\operatorname{ReLU}(\theta_m\cdot(\mathbf{x}_j+T-(\mathbf{x}_i+T))+\boldsymbol{\phi}_m\cdot(\mathbf{x}_i+T)) \\ &=\operatorname{ReLU}(\theta_m\cdot(\mathbf{x}_j-\mathbf{x}_i)+\boldsymbol{\phi}_m\cdot(\mathbf{x}_i+T)) \end{aligned} \] 当 \(\boldsymbol{\phi}_m=0\) 时,算子对平移是完全不变的。然而这会导致模型的简化,patches 的位置信息被忽略。以 \(\mathbf{x}_j-\mathbf{x}_i\) 和 \(\mathbf{x}_i\) 作为输入,既能保留全局形状信息,也能考虑到局部几何关系。
三、模型架构
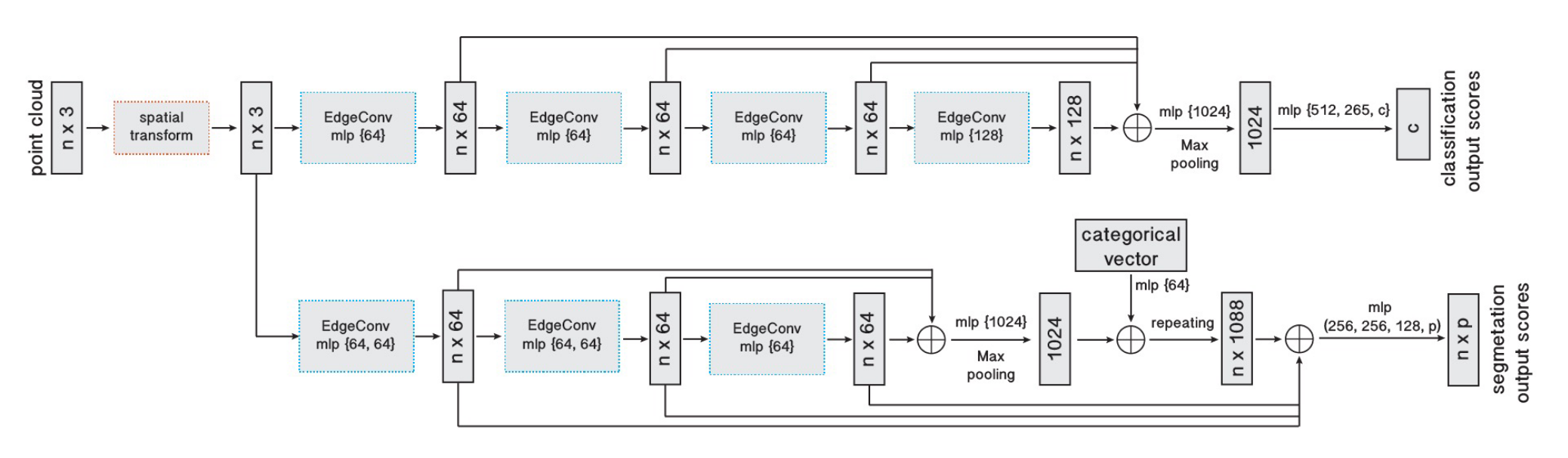
变换块(Point cloud transform block)
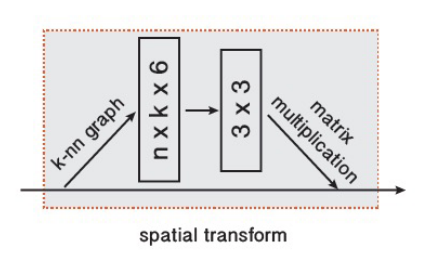
在架构的最开始,对点云应用一个 \(3\times 3\) 的矩阵变换以将其对齐。这和 PointNet 中的 T-Net 想法类似。为了学习到变换矩阵参数,构建了 \(k\) 近邻图,并提取了每个点与其相邻点的坐标差张量。
分类
输入为变换后 \(n\) 个点的坐标,在 EdgeConv 中为每个点计算大小为 \(k\) 的边特征集合,通过 MLP 扩展并聚合每个集合中的特征。不同于 PointNet++ 里的下采样,EdgeConv 并不改变点的大小和顺序,因此在多级特征组合的时候更为便利。
四个 EdgeConv 层使用了三个共享的全连接层 \((64,64,128,256)\) ,并根据每个 EdgeConv 输出的特征重新计算图,将其应用于下一层。将这几层的输出连接后得到 \(512\) 维的特征,通过一个 MLP 和池化操作将其扩展到 \(1024\) 维,并进行池化操作,最终通过一系列 MLP 得到点云全局特征。
对于超参数 \(k\) 的选取,采用了留出验证的方式来评估不同 \(k\) 对模型性能的影响。
分割
分割不同于分类的点无非在于需要同时用到每个点的全局信息和局部信息。论文采用了非常类似于 PointNet 的方法,将多层 EdgeConv 得到的全局特征(和分类部分类似)与 MLP 处理后的分类张量(categorical vector) 相连接,得到 \(1088\) 维的特征,并与前面每一层 EdgeConv 的输出相连接。最后通过一些列 MLP 将特征压缩到需要的维数。
有待确认的是,架构图中的 categorical vector 具体来自于哪一层,论文中似乎没有具体说明。
四、总结
关于 DGCNN ,主要需要关注的有以下几点:
- 考虑了点云的拓扑结构(个人觉得 PointNet++ 实际上也包含了简单的拓扑关系,但 DGCNN 的动态图使得其可能学到的更多),关注了边特征;
- EdgeConv 通过 MLP 提取边特征,通过池化来确保邻域内的置换不变性;
- 图的构建基于特征空间,在每一层对图进行更新,即所谓的动态图。这种方式让感受野变得更大、更稀疏;
- EdgeConv 很容易嵌入到其它网络中;
- 整体架构类似于 PointNet ,也就是用 EdgeConv 替换了 PointNet 中的共享 MLP 层;
与 PointNet 及 PointNet++ 的对比:
- PointNet 是 DGCNN 的一个特例,即当 \(k=1\) 时,边集为空集,边缘函数 \(h\) 为 \(h_{\Theta}(\mathbf{x}_i,\mathbf{x}_j)=h_{\Theta}(\mathbf{x}_i)\) 。换言之, PointNet 是不考虑边特征、不考虑拓扑关系的 DGCNN ;
- PointNet++ 的主要组件是 SA 层,分为下采样和 PointNet 层,每一次输出后点数减少;EdgeConv 也考虑了点的邻域,但不改变点数,因此在特征组合时无需上采样。当然 PointNet++ 也可以取消采样层从而保持点数不变,但这不是分层的本意;
- PointNet++ 利用 PointNet 层来聚合局部信息, PointNet 能够对邻域内每个点特征进行编码然后池化;EdgeConv 则对边特征进行编码,而非每个点单独的特征;
MPU
论文:Patch-based Progressive 3D Point Set Upsampling
一、摘要及引言
点云通常是稀疏、嘈杂且不完整的,这意味着上采样技术非常重要,但将图像中的超分辨率方法迁移到点云中并不容易。PU-Net 通过多尺度学习及特征扩展的方式来扩大点集,但无论输入的几何结构是大规模的还是细粒度的,PU-Net 都将使用同样的尺度来处理,以致于其重建结果往往缺乏细粒度的几何结构。
论文提出了一种 patch-based 渐进式上采样网络,将一个 \(16\times\) 上采样网络分成四个 \(2\times\) 网络,其中每个子网络侧重于不同级别的细节。
所有子网络都是完全基于 patch 的,并且输入 patch 的大小相对于当前的细节级别是自适应的。论文提出了一系列架构改进,包括用于逐点特征提取的新型密集连接、用于特征扩展的编码分配,以及用于层间特征传播的双边特征插值。这些都会在后面详细介绍。
二、相关工作
主要介绍了基于优化和基于深度学习的方法。论文指出了 PU-Net 对高分辨率输入效果较好,但缺乏细节;EC-Net 在锐利特征上有所加强,但边缘标记的工作量很大。论文还特别提到了深度学习中的多尺度 skip connection 方法,如 CNN 里的 U-Net 、ResNet 等。针对点云上采样问题,论文在不同组件中采用了不同的 skip connection 策略。
三、方法
多步上采样网络(Multi-step Upsampling Network)
多步监督(Multi-step Supervision)
Multi-step supervision 是神经图像超分辨率(neural image super-resolution)中的常见做法。简言之,对于上采样任务, Multi-step supervision 通常先将输入图像重建到一个中间分辨率,然后利用已知的高分辨率图像进行监督学习;之后再重建到更高的分辨率,再次进行学习。

这种做法的好处在于它允许模型在各个阶段学习和纠正错误,而不仅仅是在最终阶段。其次,它允许模型学习在不同分辨率之间的显式映射,这可能有助于使上采样结果更准确。
多步 patch-based 感受野(Multi-step patch-based receptive field)
理想情况下,点集上采样网络应针对各种细节尺度自适应地跨越感受野,以从多个尺度学习几何信息。然而不同于图像,点集没有规则结构,每个点的邻域都需要通过 \(k\) 近邻的方式去查找,计算代价非常大,这使得多步上采样难以应用在点云中。因此有必要优化网络架构,使其可扩展到高分辨率点集。
论文应对这一问题的关键想法是:patch 大小应适应当前步骤的感受野范围。感受野的范围实际上由 \(k\) 的大小决定,若 \(k\) 固定,则随着点集不断被上采样,感受野会变小。因此论文提出的网络在上采样的同时,缩小了 patch 的空间跨度,减少了计算量。
由于需要对每个点做 KNN ,设总点数为 \(N\) ,patch 大小为 \(p_{num}\) ,其计算复杂度可以大约估算: \[ O=p_{num}^2\times \frac{N}{p_{num} }= N\times p_{num} \] 因此随着 patch 大小缩减,计算复杂度也会降低。
多步端到端训练(Multi-step end-to-end training)
网络通过 \(L\) 步将点集上采样 \(2^L\) 倍,包括子网络单元 \(\{U_1,U_2,\dots,U_L\}\) 。论文通过逐步激活每个单元的方式来训练这一系列上采样单元。具体地,除了第一层网络,每一层网络的训练都包含两步:对于层次 \(\hat{L}\) ,首先固定前面 \(U_1\) 到 \(U_{\hat{L}-1}\) 每一层的参数,只对 \(U_{\hat{L}}\) 层训练;然后释放固定单元,对所有单元同时训练。
这种渐进式的训练方法是为了避免当前层产生过大的梯度(gradient turbulence),导致前面的单元参数被破坏。
上采样网络单元
分别用 \(T,P,Q\) 表示基准模型、预测 patch 和 参考 patch ,\(\hat{L},\ell\) 表示目标的细节级别和一个中间级别。简单来说,上采样网络单元 \(U_{\ell}\) 首先接收来自于点集 \(P_{\ell-1}\) 的 patch ,然后提取深度特征并扩展特征数量,将特征通道数压缩到 \(d\) 维坐标 \(P_{\ell}\) 。下面做详细说明。
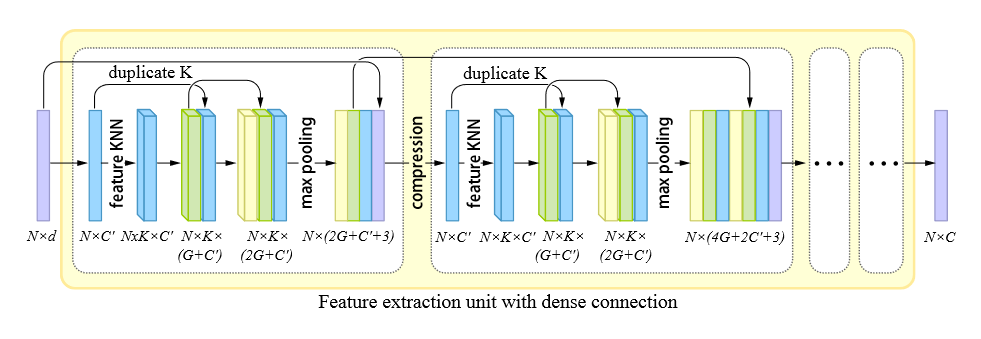
通过层内密集连接提取特征
在 PointNet++ 之后,大多数网络都采用对输入点集进行分层下采样的方式来提取多尺度信息,并采用 skip-connections 来连接多级特征。然而由于在下采样过程中采用了泊松盘采样或者最远点采样,导致点的位置发生变化,因此在特征连接的时候,需要进行点与点之间的对应搜索,导致计算代价增加。
收到 DGCNN 的启发,论文在特征空间中定义了局部邻域,因此网络无需点集子采样即可获得大范围、非局部的信息,也就不需要在特征组合时进行对应搜索。
如下图所示,论文的特征提取单元由一系列密集块(dense block)组成。在每个 dense block 中,首先将输入转换为固定维数 \((C')\) 的特征,然后使用基于特征的 KNN 对特征进行分组,得到分组特征 \((N\times K\times C')\) 。进而通过 MLP ,将特征重组为 \(G'\) 维。实际上,在每个 dense block 内部,MLP 的输出维度都是固定的 \((G')\) ,并且每经过一次特征处理,就会将上一步的特征拼接在后面,因此每一次处理都使得特征维数增加 \(G'\) 。最后通过最大池化得到一个顺序不变的点特征。而在 dense blocks 之间,每个块产生的点特征会作为后面所有的 dense blocks 的输入(因为 dense block 的输出也会和上一个 block 的输出连接。相当于内部外部嵌套地进行 skip connections )。
这种 skip-connection 的方式能够复用显式信息,从而提高重建精度。同时相比于 PU-Net 在每一次下采样后用 PointNet 层聚合特征的方式,论文的特征提取方法能够显著减小模型参数量。
通过编码分配扩展特征
特征扩展单元的目标是将提取得到的特征 \((N\times C)\) 扩展为一组上采样的点坐标 \((2N\times d)\) 。PU-Net 的策略是复制每个点的特征,然后通过独立的 MLP 去处理所有的复制特征。但这会造成点的集中分布,PU-Net 通过添加了排斥损失来缓解这一问题。
论文借鉴了 FoldingNet 和 AtlasNet 。简单浏览了一下 FoldingNet ,大致思路是:首先从三维模型中提取了全局特征,然后复制一定数量,连接到一个二维网格点后面,将其重建为三维点,再次将复制后的全局特征连接到三维点后,重建成最终的具有预设数量的三维点。
论文的方法则更为简单,它将 \(N\) 个 \(-1\) 和 \(N\) 个 \(1\) 组成的一维张量拼接在复制了两份的特征向量后面(code assignment),再利用一系列共享的 MLP 将其压缩为 \(2N\times d\) 的残差。将残差和原始坐标求和即得到新的上采样坐标,这与 EC-Net 的做法是一样的。区别于 PU-Net 和 EC-Net 在特征扩展部分所采用的策略,共享的 MLP 意味着参数量不会随着上采样率增大而增大(突然有个想法,如果后面接的特征不是 \(1\) 和 \(-1\) ,而是在 \(4\pi\) 空间上均匀采样的 \(2N\) 个方位角呢,会不会发散得更合理)。
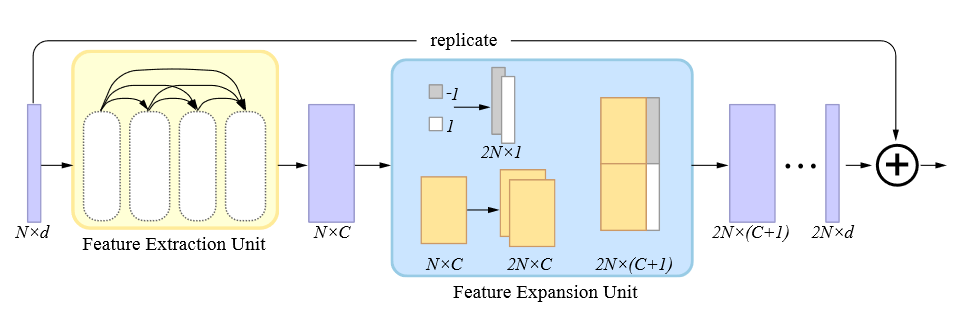
通过双边特征插值实现层间 skip connection
上述两个组件已经实现了特征的嵌入和特征的扩展,这两者合在一起构成一个上采样单元。为了融合不同感受野提取的特征,论文在多个上采样单元之间使用了 skip connection 。由于点数增长,在连接之前需要进行特征插值。对于级别 \(\ell\) ,\(p_i\) 表示第 \(i\) 个点坐标,\(f_i\) 表示通过特征提取组件得到的该点特征。\(\mathcal{N}_i'\) 表示第 \(p_i\) 在级别 \(\ell'\) 中的空间 KNN 近邻点集,则插值特征 \(\widetilde{f}_i\) 表示为:
\[ \widetilde{f}_i = \frac{\sum_{i'\in \mathcal{N}_i'}\theta(p_i,p_{i'})\psi(f_i,f_{i'})f_{i'}}{\sum_{i'\in \mathcal{N}_i'}\theta(p_i,p_{i'})\psi(f_i,f_{i'})} \]
显然 \(\theta\) 和 \(\psi\) 是两个权重函数。其中 \(\theta(p_1,p_2)=e^{-\left(\frac{\|p_1-p_2\|}{r}\right)^2},\psi(f_1,f_2)=e^{-\left(\frac{\|f_1-f_2\|}{h}\right)^2}\) ,\(r\) 和 \(h\) 是到附近点的(特征)距离平均值。这也就是所谓的双边插值(bilateral interpolation),即同时考虑空间相似度和特征相似度的插值方式。
实现层间连接的方式可以是对先前所有层的 \(\widetilde{f}_i\) 进行插值和连接,即密集连接,这和特征提取单元是一样的。但是这样做意味着第 \(\ell\) 层会有 \(\ell C\) 个特征,导致扩展性差、优化困难。因此论文采用了残差跳跃连接,每个级别只需要和上一个级别的特征相连,这在下图中展现得很清楚。

实施细节
迭代提取 patch
训练
\(P_{\hat{L}},Q_{\hat{L}}\) 分别表示预测和参考 patch ,\(T_{\hat{L}}\) 则表示该分辨率下的整体参考点云。在渐进式上采样过程中,则会有一系列预测和参考 patch ,记作 \(P_{\ell},Q_{\ell}\) ,其中 \(\ell=1\dots\hat{L}-1\) 。
具体来说,\(\ell\) 层的输入是通过对 \(P_{\ell-1}\) 中的随机点 \(p_{\ell-1}'\) 执行 KNN 搜索得到的,其中 \(k=N\) ,为 patch 的大小。而 \(\widetilde{Q}_{\ell}\) 应与 \(P_{\ell}\) 的空间范围相匹配,同时具有更高的分辨率,因此 \(Q_{\ell}\) 可以通过在 \(Q_{\ell-1}\) 中执行 KNN 得到,并且查询点仍为 \(p_{\ell-1}'\) 。此时 \(k=2^{\hat{L}-\ell+1}N\) (这里符号表示和原文不同,因为 * 有转义字符的含义,网页里似乎优先级高于公式)。
关于这个结论,可以先考虑第 \(1\) 层:我们希望将第一层的 \(N\) 个点上采样为 \(2^{\hat{L}}\) 个点,因此在参考点云中,需要采样 \(2^{\hat{L}-0}=2^{\hat{L}}\) 个点;而点云被上采样 \(\ell-1\) 次之后,到达了 \(\ell\) 层,此时需要在参考点云中采样的点数变为 \(2^{\hat{L}-(\ell-1)}=2^{\hat{L}-\ell+1}\) 。如下图所示,需要注意的是 \(Q_{\ell}\) 的分辨率是不随 \(\ell\) 变化的,仅仅是空间范围变化而已,换言之,\(\left|P_{\ell}\right|/\left|Q_{\ell}\right|\) 等于 \(P_{\ell}\) 和基准点云的分辨率之比,随着上采样次数增加,\(P_{\ell}\) 的分辨率增大,patch 点数不变的情况下, \(Q_{\ell}\) 的点数随之减少。
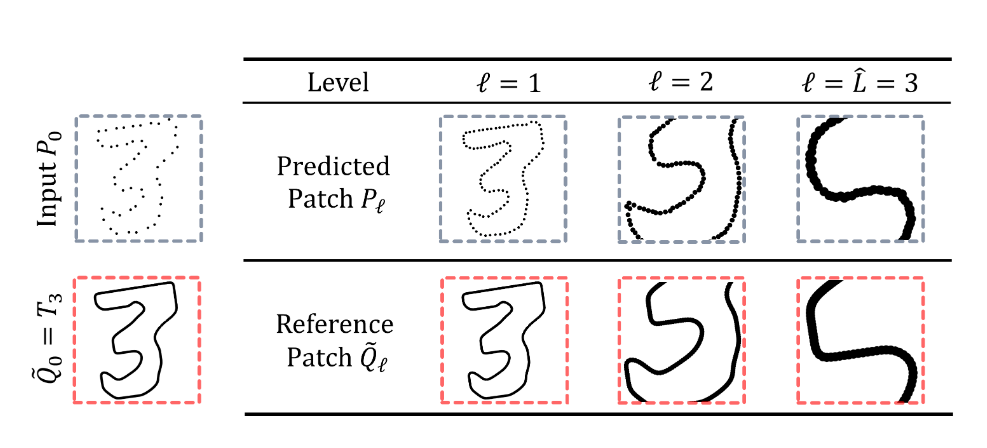
推理
推理阶段和训练主要有两个不同:
- 对于每个级别,提取 \(H\) 个有重叠的输入 patches 以确保覆盖整个点集。patch 的中心点通过最远点采样获得;
- 由于有重叠,上采样后的点数实际上大于 \(2\left|P_{\ell-1} \right|\) ,因此对 \(P_{\ell}\) 进行最远点采样,使其点数为上一层的两倍。这同样有助于上采样结果均匀分布。
损失函数
考虑到计算速度,论文采用了欧氏距离进行 patch 提取,但这可能导致 \(P_{\ell}\) 和 \(Q_{\ell}\) 的边缘产生错位问题,也就是空间范围不一致。为了降低这些不匹配点带来的噪声,论文提出了改进的 Chamfer 距离: \[ \mathcal{L}(P,Q)=\frac{1}{\left|P\right|}\sum_{p\in P}\xi(\underset{q\in Q}{\min}\left\|p-q \right\|^2)+\frac{1}{\left|Q\right|}\sum_{q\in Q}\xi(\underset{p\in P}{\min}\left\|p-q \right\|^2), \\ \xi=\left\{\begin{aligned}&d,\ \ d\leq\delta\\&0,\ \ \text{otherwise} \end{aligned} \right. \] 相比于之前在 PU-Net 里所介绍的 CD 距离,其实就差了一个 \(\xi\) 函数。其中 \(\delta\) 设置为平均最近邻距离的倍数,以便动态调整到不同尺度的 patch (至于为什么是倍数,可能因为尺度较大时这个条件可以被适当放宽?)。
四、总结
论文所做的主要工作包括:
- 提出了新的特征提取和特征扩展单元,其中特征提取部分在特征空间上定义了邻域,无需下采样,避免了特征连接需要点对应搜索的问题,并通过密集连接复用信息;特征扩展部分采用了附加变量的方式,使用共享的 MLP ,起到控制参数量、促使点均匀分布的作用;
- 在不同层之间利用双边插值进行残差连接,同时考虑特征距离和空间距离;
- 随着不断上采样、感受野缩小的同时,缩小了 patch 的空间跨度,即自适应 patch 。这使得网络可以端到端地训练;
AR-GCN
论文:Point Cloud Super Resolution with Adversarial Residual Graph Networks
一、方法
AR-GCN 方法概述
AR-GCN 由两个网络组成,生成器 \(G\) 和鉴别器 \(D\) 。其中 \(G\) 通过逐步上采样输入的 LR 来生成 HR 点云,而 \(D\) 负责辨别 HR 点云是真还是假。
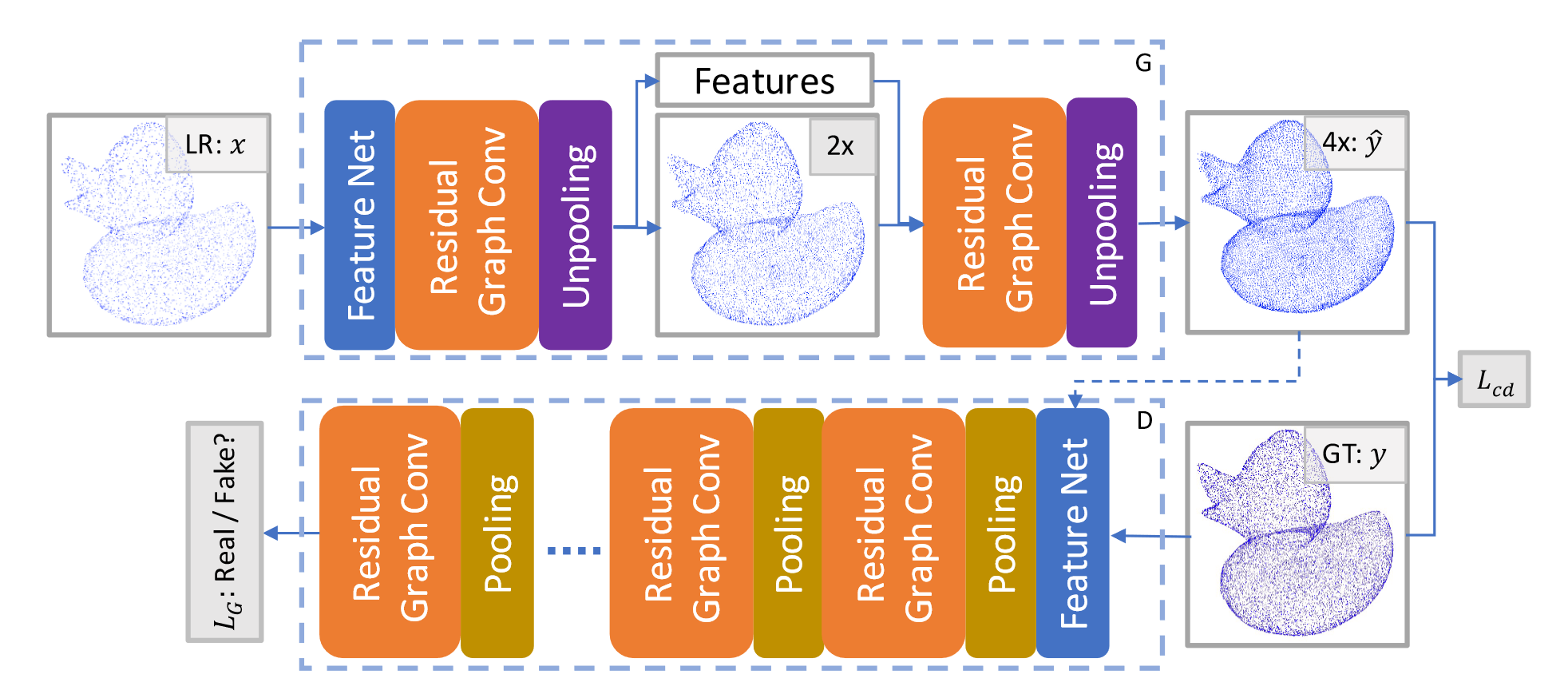
论文提出了一个联合损失函数: \[ L(x,y)=\lambda L_{cd}(G(x),y)+L_G(G(x)) \] 其中 \(\lambda\) 控制损失函数 \(L_{cd}\) 和 \(L_G\) 的权重比。\(L_{cd}\) 度量了 \(y\) 和 \(\hat{y}\) 之间的距离,类似于图像超分辨率中的 \(L_2\) 损失: \[ L_{cd}(\hat{y},y)=\sum_{p\in y}min_{q\in\hat{y}}\|p-q\|_2^2 \] \(L_{cd}\) 是 CD 距离的变体。原始倒角距离由两部分组成:\(L_{cd}\) 和 \(\hat{L}_{cd}\) ,两者形式上对称。但 \(\hat{L}_{cd}\) 会促使预测点云 \(\hat{y}\) 与输入相同,导致点云出现重复点(后续可以实验证明一下)。因此论文删去了 \(\hat{L}_{cd}\) 。
\(L_G\) 损失则借鉴了 LSGAN(最小二乘生成对抗网络),被称作图对抗损失。LSGAN 主要工作是将 GAN 中的交叉熵损失函数替换为了最小二乘损失函数,克服了原始 GAN 生成结果不稳定、图像质量差的问题。具体有关 GAN 网络的原理及改进,在我另一篇笔记中有详细说明。以此有生成器和鉴别器的训练指标: \[ \begin{aligned} L_G(\hat{y})&=\left\|1-D(\hat{y}) \right\|^2_2 \\ L_D(\hat{y},y)&=\frac{1}{2}\|D(\hat{y}) \|^2_2+\frac{1}{2}\|1-D(y) \|^2_2 \end{aligned} \] 简单来说,AR-GCN 使用了生成对抗网络,生成器和鉴别器的损失函数借鉴了 LSGAN 的定义方法;此外,问题的本质仍然是上采样问题,因此加入点云间的相似性度量,指导生成器的训练。论文通过设计新的联合损失函数,将 GAN 和点云上采样结合了起来。
残差图卷积生成器
首先来看生成器的组成。生成器的目标是将点云上采样,包含了残差图卷积块、反池化块以及特征网络。
残差图卷积块
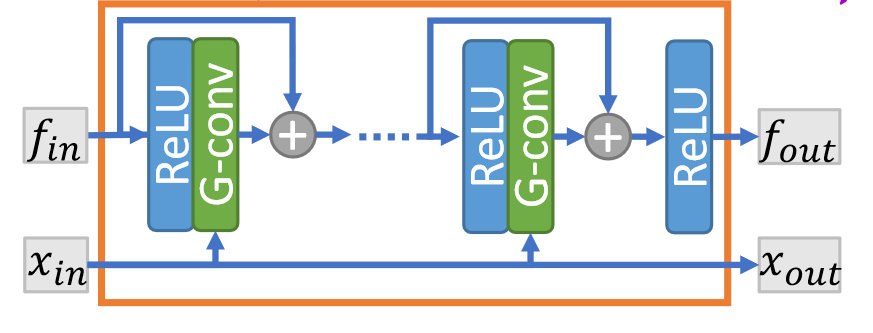
作者认为 PointNet++ 对中心点邻近点一视同仁,而图卷积的性能更加优异。观察上图,对于输入的特征 \(f_{in}\) 和输入点云 \(x_{in}\) ,通过 \(x_{in}\) 在每次卷积时查询近邻点 \(N(p)\) ,则每一层卷积的运算为: \[ f_{i+1}^p = w_0 f_l^p + w_1\sum_{q\in N(p)}f_l^q,\forall p\in v \] 其中 \(w_0,w_1\) 是可学习的参数,\(x_{in}\) 和 \(x_{out}\) 没有区别。同时注意到块中引入了残差连接来提升性能。思路和 DGCNN 很类似,但 DGCNN 更关注边特征,而这里以点特征为主体。同时 DGCNN 的图是动态更新的,也是一点不同。
反池化块
反池化的目的是增加点的数目。它首先通过残差图卷积块中的 G-Conv 层,将特征转换为 \(\hat{n}\times 6\) 的张量,然后重塑为 \(\hat{n}\times2\times3\) ,记作 \(\delta x\) ,然后将原始点坐标复制一份,加到坐标残差上。反池化块的宗旨是预测输入点和输出点之间的残差,比直接预测点坐标更快,这在 EC-Net 中就有阐述。
反池化块仅仅重塑了坐标,但破坏了特征。因此论文依然利用残差图卷积块所得到的特征,进行插值得到新点云 \(x_{out}\) 中每点的特征: \[ f_{out}^p = \frac{1}{k}\sum_{q\in N_{x_{in}}(p)}f_{in}^q,\forall p\in x_{out} \] 可以看到,此处对最近邻搜索 \(N(p)\) 标注了搜索集合为 \(x_{in}\) ,但计算的点坐标是来自 \(x_{out}\) 的。个人觉得,如果把预测的残差和原始特征放进一个图卷积来预测新的特征,或许会更好一些,这里相当于直接用了平均池化层。
特征网络
在进入残差图卷积块之前,需要提取点特征。论文采用了简单的 PointNet 结构,对每个点获取最近邻点,得到张量 \(k\times 3\) ,然后通过一系列逐点卷积加上一个最大池化层,转换为 \(1\times c\) 的特征 \(f^p\) 。
渐进式上采样
另外,论文采用了两次 \(2\times\) 的上采样,并在实验中发现这样做的精度更好。
图判别器
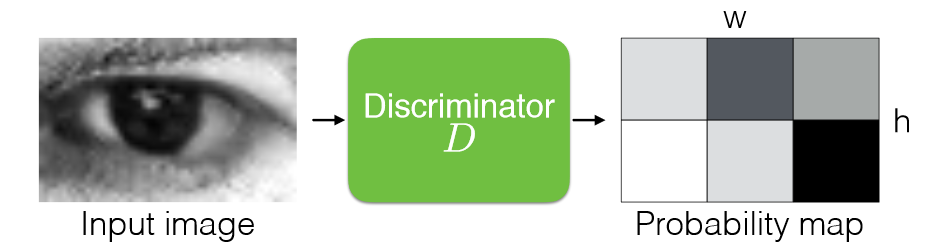
图判别器的结构依然基于残差图卷积块和特征网络,事实上,从第一张图可以看出,判别器和生成器唯一的区别就是用池化层替代了反池化层,最终输出一个标量预测。池化层的运算方法很简单,首先将点进行最远点采样,然后计算剩余点的特征为周围近邻点特征的池化: \[ f_{out}^p =\max_{q\in N_{x_{in}}(p)}f_{in}^q,\forall p\in x_{out} \] 特别的是,论文没有采用逐步下采样至单个标量的方式,因为这样做会导致伪像(我的理解是一些细微的噪声很难被整体鉴别器察觉,导致生成的数据上有伪影)。因此在这里鉴别器的输出包含不止 1 个点,并对每个点的局部 patch 进行鉴别,通过交叉熵来计算最终的总损失值。这里实际上是借鉴了另一篇文章:Learning from Simulated and Unsupervised Images through Adversarial Training ,下图很直观地说明了这种方法。
二、总结
主要的思路和方法就是以上这些,论文原文讲得非常详细。总得来说,AR-GCN 很好地在上采样过程中结合了 GAN 的思路,因此对于未见过的数据集有更强的泛化能力,能够生成细节更丰富的结果。并且通过回归坐标残差来提升收敛速度和稳定性,通过渐进式上采样取得更优的效果。
PU-GAN
论文:PU-GAN: a Point Cloud Upsampling Adversarial Network。这篇比 AR-GCN 发表时间略早,思路也都是结合 GAN 。
一、方法
生成器
生成器包含了三个组件,下面一一介绍。
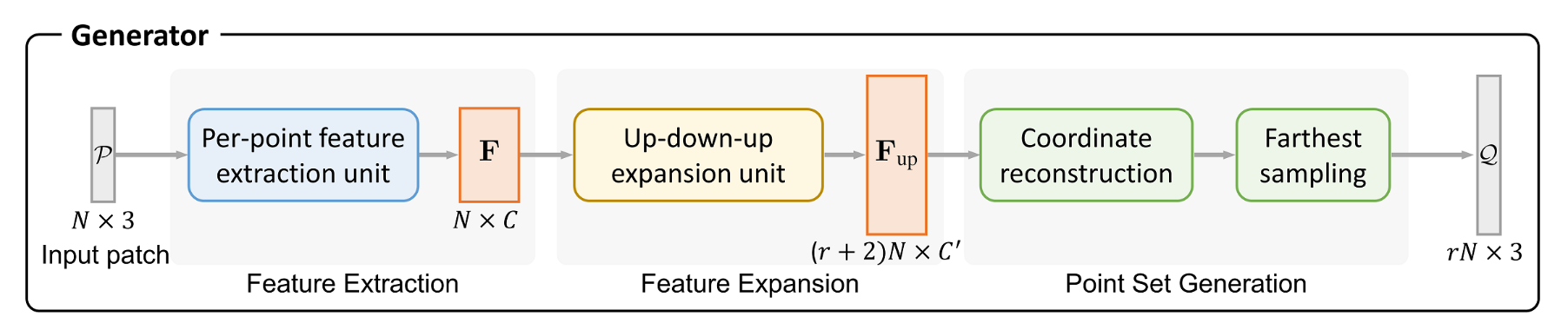
逐点特征提取单元(Per-point feature extraction unit)
PU-GAN 采用了 MPU 中的特征提取方法,这在上文 MPU 一节中有详细说明。简言之,它使用了层内密集连接来复用显式信息,同时借鉴 DGCNN 在特征空间上定义邻域,无需下采样就可以得到每个点的特征。
特征扩展组件(Feature Expansion Component)
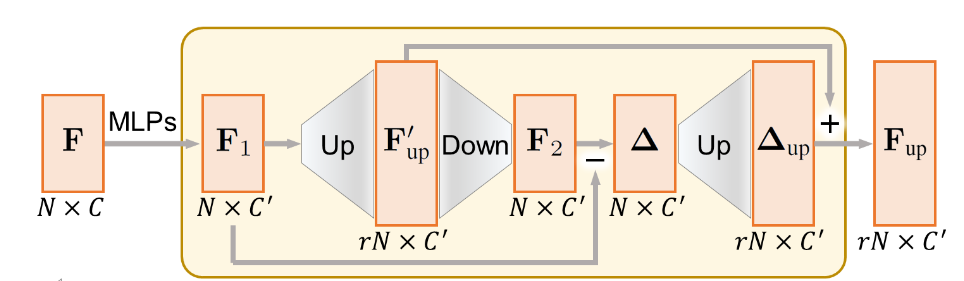
论文提出了一个自上而下的扩展单元,称为 Up-down-up Expansion Unit 。简单来说,它首先将点特征\(\mathbf{F}_1\)上采样为 \(\mathbf{F}_{up}'\) ,然后下采样为 \(\mathbf{F}_2\) ,并计算上采样前和下采样后的特征差异,记作 \(\Delta\) 。然后再将 \(\Delta\) 上采样为 \(\Delta_{up}\) ,并和 \(\mathbf{F}_{up}'\) 相加,得到最终的上采样特征 \(\mathbf{F}_{up}\) 。
特征上采样
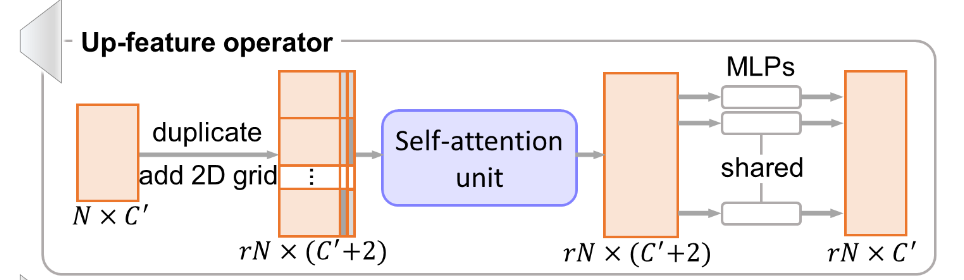
上采样组件 Up-feature operator 为了避免 PU-Net 中生成点太接近的问题,将特征复制后,对于每一个特征及其副本,在二维格网上采样向量并拼接到后面,使得每一个副本都不一样。和 MPU 不同,PU-GAN 对 FoldingNet 借鉴得更彻底。
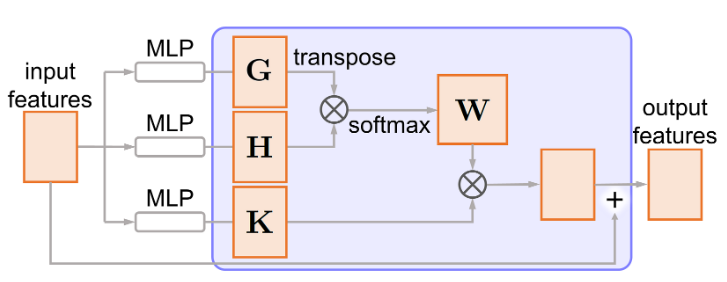 接着引入了自注意力机制,具体如左图所示。首先将输入特征通过两个单独的密集连接层,分别得到
\(\mathbf{G}\) 和 \(\mathbf{H}\) ,从而得到注意力权重 \(\mathbf{W}\) : \[
\mathbf{W}=f_{\text{softmax}}(\mathbf{G}^T\mathbf{H})
\] 然后通过 \(\mathbf{K}\)
得到权重矩阵 \(\mathbf{W}^T\mathbf{K}\)
。最后将权重矩阵和输入矩阵求和,得到输出矩阵。在这里自注意力单元不改变输入特征的尺寸。
接着引入了自注意力机制,具体如左图所示。首先将输入特征通过两个单独的密集连接层,分别得到
\(\mathbf{G}\) 和 \(\mathbf{H}\) ,从而得到注意力权重 \(\mathbf{W}\) : \[
\mathbf{W}=f_{\text{softmax}}(\mathbf{G}^T\mathbf{H})
\] 然后通过 \(\mathbf{K}\)
得到权重矩阵 \(\mathbf{W}^T\mathbf{K}\)
。最后将权重矩阵和输入矩阵求和,得到输出矩阵。在这里自注意力单元不改变输入特征的尺寸。
特征下采样
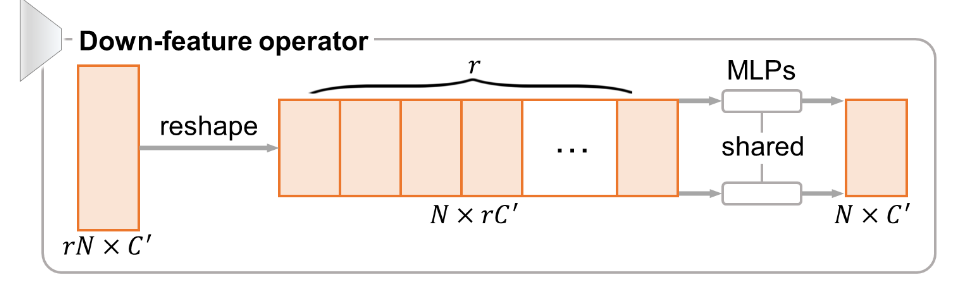
下采样单元的思路则非常简单,直接将 \(rN\times C'\) 的特征 reshape 为 \(N\times rC'\) ,然后通过一组共享的 MLPs 将特征变回原来的尺寸 \(N\times C'\) 。
点集重建组件
为了增强生成点的均匀性,PU-GAN 首先通过一组 MLPs 生成一组点坐标,然后通过最远点采样得到 \(rN\) 个点。因此在上采样阶段,需要上采样到更高的倍数,论文中使用了 \((r+2)N\) 。
判别器
接着看一下判别器的组成。
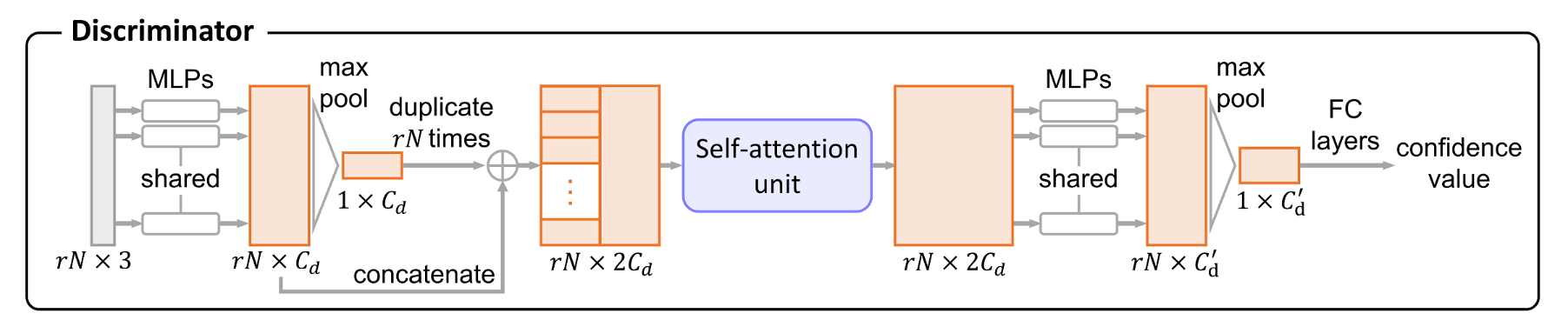
对于输入的高分辨率点坐标 \(rN\times 3\) ,首先通过共享 MLPs 和池化层得到全局特征 \(1\times C_d\) ,并复制 \(rN\) 份,和点特征 \(rN\times C_d\) 拼接。通过注意力机制单元增强特征,然后再通过一组共享的 MLPs 和池化层得到全局特征,最后以一组全连接层回归置信度。若置信度接近 1,则判别器将其预测为真实数据,反之为生成数据。
损失函数
为端到端训练网络,论文设计了复合的损失函数。
对抗损失
和 AR-GCN 一样,PU-GAN 采用 LSGAN 的最小二乘损失作为对抗损失,定义如下: \[ \begin{aligned} \mathcal{L}_{\text{gan}}(G)&=\frac{1}{2}(D(\mathcal{Q})-1)^2 \\ \text{and }\ \mathcal{L}_{\text{gan}}(D)&=\frac{1}{2}\left[D(Q)^2+(D(\hat{Q})-1)^2\right] \end{aligned} \]
均匀损失(Uniform Loss)
单独使用对抗网络难以使网络收敛,也很难生成均匀的点集。因此需要一个统一的损失来评估生成的 \(\mathcal{Q}\) ,从而提高生成器的生成能力。PU-Net 使用 NUC 指标来评估点集表面的均匀性,主要思路是在物体表面放置大小相同的圆盘并统计圆盘内的点数变化差异。但这样做忽略了圆盘内点的局部混乱。
论文的方法如下。首先对 patch 进行最远点采样,得到 \(M\) 个种子点,并使用球查询半径 \(r_d\) 获取一系列局部点子集,记作 \(S_j,\ j=1,2,\dots,M\) 。这里的 \(r_d\) 取较小的值,使得 \(S_j\) 中的点大致位于一个小局部圆盘上,面积为 \(\pi r_d^2\) 。另一方面,通过测地线距离形成 patch 并标准化到单位球体当中,此时面积为 \(\sim\pi 1^2\) 。因此 \(S_j\) 中点的百分比应为 \(p=(\pi r_d^2)/(\pi1^2)= r_d^2\) 。需要注意,此时的 patch 是标准化的,因此 \(r_d<1\) 。得到 \(\hat{S_j}\) 中的期望点数为 \(\hat{n}=rN\times p\) 。PU-GAN 遵循卡方模型来度量 \(|S_j|\) 的偏差: \[ U_{\text{imbalance}}(S_j)=\frac{(|S_j|-\hat{n})^2}{\hat{n}} \] 为了计算局部的点混乱,对于 \(S_j\) 中的每个点,找到其最近邻点的距离,记第 \(k\) 个最近点的距离为 \(d_{j,k}\) 。如果点是均匀分布的,那么假设 \(S_j\) 完全平坦且点成六边形分布,则预期的点到邻近点距离 \(\hat{d}\) 应为 \(\sqrt{\frac{2\pi r_d^2}{|S_j|\sqrt{3}}}\) 。这个计算是比较粗糙的,它假设了点数等于三角形数,那么三角形面积为 \(\frac{\sqrt{3}}{2}\hat{d}^2=\frac{\pi r_d^2}{|S_j|}\) ,即可推得。同样地,遵循卡方模型来度量 \(d_{j,k}\) 的偏差: \[ U_{\text{clutter}}(S_j)=\sum_{k=1}^{|S_j|}\frac{(d_{j,k}-\hat{d})^2}{\hat{d}} \] 根据上述定义可知,\(U_{\text{imbalance}}\) 描述了非局部的分布均匀性,而 \(U_{\text{clutter}}\) 描述了局部的分布均匀性,这是对 NUC 指标的改良。最终计算均匀损失为: \[ \mathcal{L}_{\text{uni}}= \sum_{j=1}^M U_{\text{imbalance}}(S_j)\cdot U_{\text{clutter}}(S_j) \]
重建损失(Reconstruction Loss)
当然不能忘了上采样原本的目的:让生成的点位于表面上。PU-GAN 使用了 EMD 距离来衡量生成点云和实际点云的距离,记作 \(\mathcal{L}_{\text{rec}}\) 。
联合损失
最终定义生成器和鉴别器的训练损失分别为: \[ \begin{aligned} \mathcal{L}_G=&\lambda_{\text{gan}}\mathcal{L}_{\text{gan}}(G)+\lambda_{\text{rec}}\mathcal{L}_{\text{rec}}+\lambda_{\text{uni}}\mathcal{L}_{\text{uni}} \\ \text{and }\ \mathcal{L}_D=&\mathcal{L}_{\text{gan}}(D) \end{aligned} \]
二、总结
PU-GAN 最早将生成网络应用于点云上采样,在上采样以及判别器模块中结合了注意力机制加强特征融合。同时为了追求均匀分布的点,设计了能够兼顾局部和非局部点均匀性的损失函数。独特的 up-down-up 特征扩展单元被称为具有所谓的“自我校正”功能,我的理解是在上采样时扩展了特征维度,但一次扩展不一定准确,所以相当于算两遍特征。不过我不是很懂这个结构怎么被设计出来的,可能还是境界不够。
PU-GCN
论文:PU-GCN: Point Cloud Upsampling using Graph Convolutional Networks
代码:PU-GCN: Point Cloud Upsampling using Graph Convolutional Networks (github.com)
一、方法
上采样方法
在此之前,PU-Net 使用并联的两层 MLP 扩展特征,MPU 对拼接了一维张量的特征向量使用共享 MLP 回归残差坐标,AR-GCN 直接将特征重塑成坐标的维数然后展开。PU-GCN 受图像超分辨率中 PixelShuffle 的启发,提出 NodeShuffle 来有效地对点云进行上采样。
PixelShuffle 是插值、转置卷积之外的一种流行的上采样方式。对于尺寸为 \(C\times H\times W\) 的图像,通过可学习参数将特征重塑为 \(C r^2\times H\times W\) ,然后按照顺序排布,得到 \(C\times Hr \times Wr\) ,即实现了上采样。下图给出了一个 \(3\) 倍上采样的示意图,可以看到最后的高分辨率图中每个九宫格都是一样的顺序排布,也即所谓的 “周期性” 洗牌。
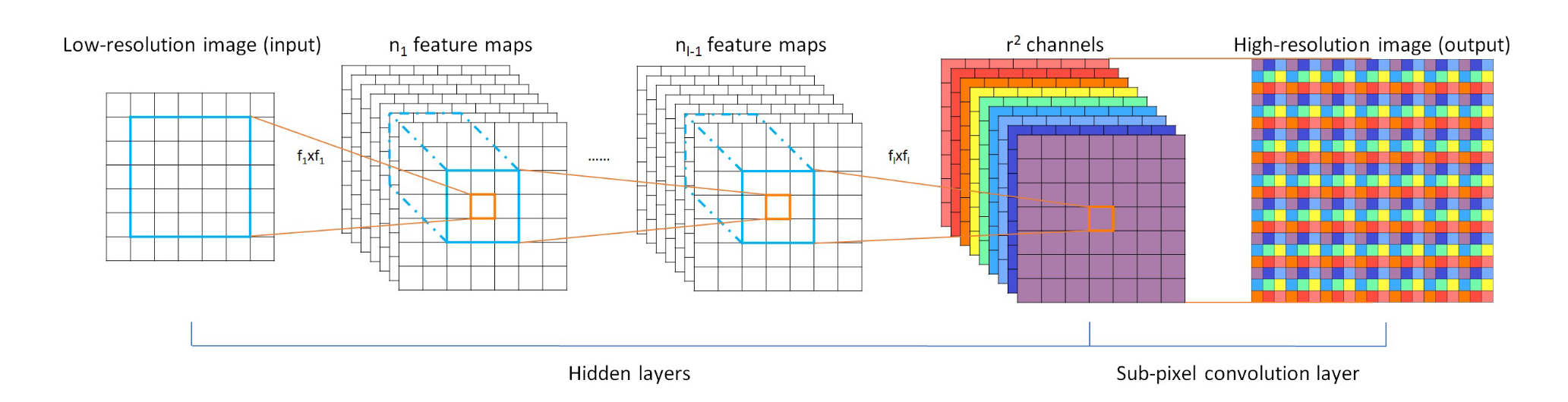
我们很容易就可以建立下标之间的对应关系: \[ \mathcal{PS}(I)_{x,y,c} = I_{\lfloor x/r \rfloor, \lfloor y/r \rfloor, C\cdot \text{mod}(x,r)+c} \] 而对于点云来说,这一操作更加简单。NodeShuffle 操作可以分为两个步骤。
- 通道扩展:使用 1 层 GCN 使用可学习参数 \(\mathcal{W}_{l+1}\) 和 \(b_{l+1}\) 将节点特征 \(\mathcal{V}_l\) 扩展为 \(N × rC\) 的尺寸。
- 周期性改组:重新排列通道扩展的输出以形成 \(rN × C\) 。
与多分支 MLP 或基于重复的上采样相比,NodeShuffle 利用图卷积而不是 CNN。尽管 GCN 是特征提取的常见模块,但 PU-GCN 第一次将其用于点云上采样。论文认为上采样的关键是对来自点邻域的空间信息进行编码,并从潜在空间中学习新点。
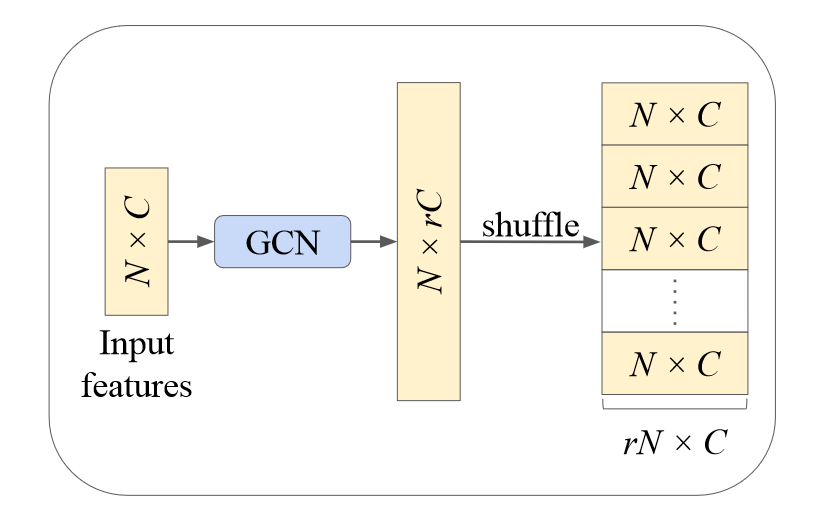
NodeShuffle 和 AR-GCN 中的反池化块在思路上几乎是一样的,区别在于 NodeShuffle 返回了特征,而 AR-GCN 中返回坐标残差,并用插值得到对应点特征。而且 NodeShuffle 返回的特征实际上仍然是一个图,可以进行更多的处理。
NodeShuffle 的设计方式使其更通用,能够植入到任意的上采样框架中。看来细微的设计差异也能带来很大的不同啊。
多尺度特征
为了对点云的多尺度性质进行编码,论文提出了一种新的 Inception DenseGCN 特征提取器,它将 DeepGCNs 中的密集连接 GCN 模块(DenseGCN) 有效地集成到 GoogLeNet 中的 Inception 模块中。
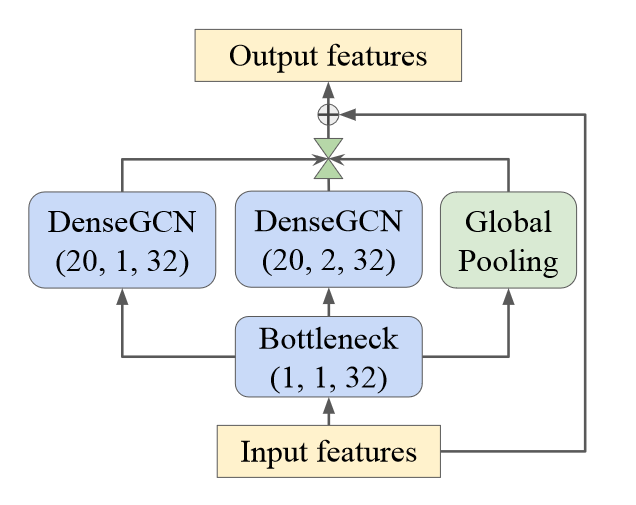
GoogLeNet 中的 Inception 模块的主要思想是通过多个并行的不同大小的卷积核以及池化层来处理图像,并将特征连接。事实证明,残差连接和密集连接对于提高点云处理性能非常有用。在这里,论文更多采用密集连接而非残差连接,因为前者利用了先前层的特征以及不同的 Inception 路径。
二、总结
主要的思路和方法就是以上这些,论文原文讲得非常详细。总得来说,PU-GCN 很好地在上采样过程中结合了 GAN 的思路,因此对于未见过的数据集有更强的泛化能力,能够生成细节更丰富的结果。并且通过回归坐标残差来提升收敛速度和稳定性,通过渐进式上采样取得更优的效果。